RepoForge: Training a SOTA Fast-thinking SWE Agent with an End-to-End Data Curation Pipeline Synergizing SFT and RL at Scale
2025-07-17
TL;DR
The Problem: Training software engineering (SWE) LLMs is bottlenecked by expensive infrastructure, inefficient evaluation pipelines, scarce training data, and costly quality control.
Our Solution: RepoForge - an autonomous, end-to-end pipeline that generates, evaluates, and trains SWE agents at scale. In particular, we present:
- 🚀 RepoForge-8B-Agent: achieves 17.4% on SWE-Bench Verified 1 (new SOTA for ≤8B non thinking LLMs)
- 📊 7,304 executable environments auto-generated from real GitHub commits (with zero manual intervention)
- 💾 14× storage reduction: 1.4 GB → 102 MB per instance via intelligent dependency management and lineage image reuse
- ⚡ > 70% faster evaluation using a Ray-powered 2 distributed RepoForge harness
- 🏷️ 19,000× cheaper labeling through our automated SPICE 23 difficulty assessment technique
Introduction
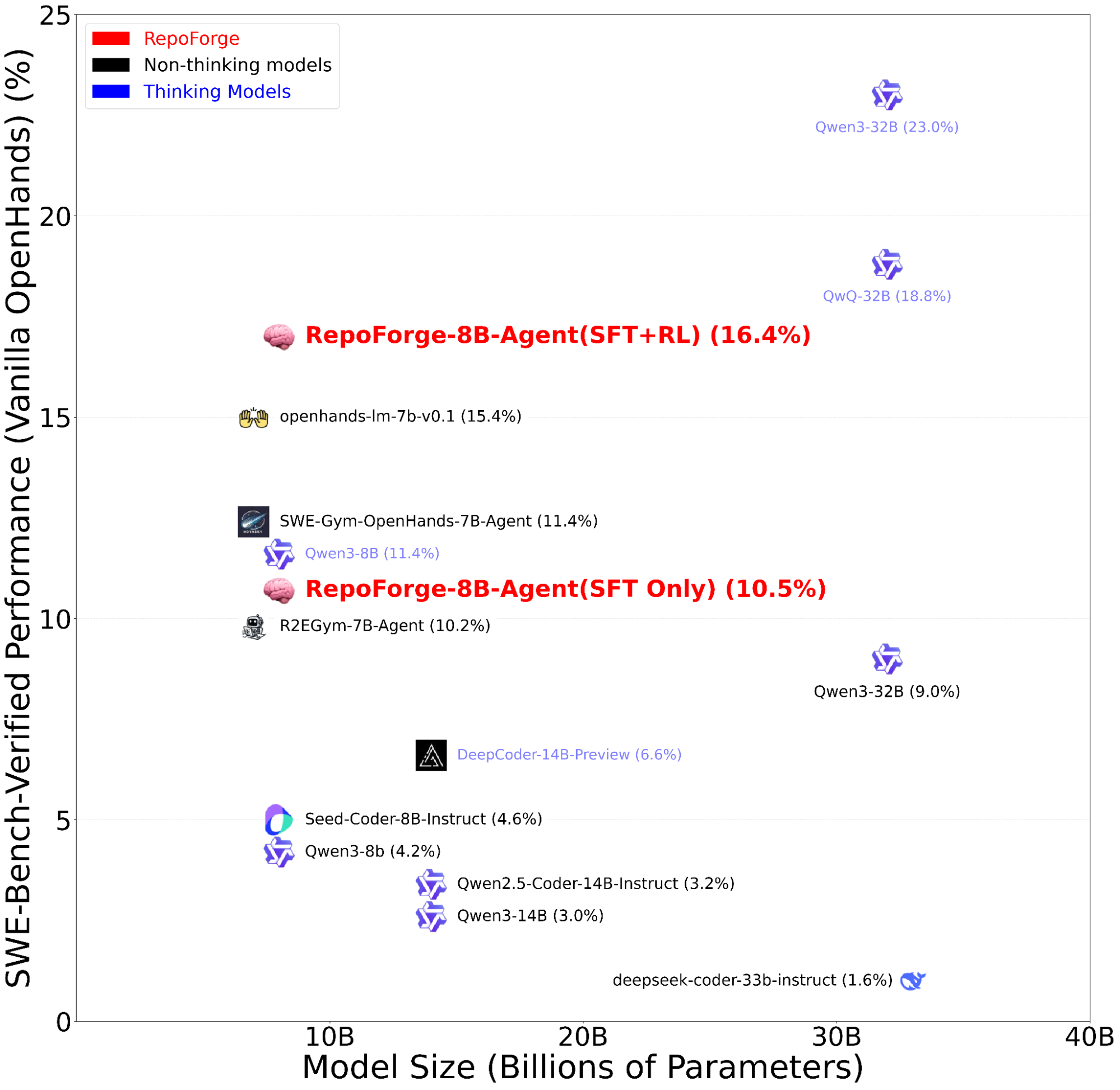
Figure 1: SWE-Bench Verified Performance vs. Model Size for LLM Coding Agents with the official OpenHands3 tested in-house. RepoForge-8B-Agent stands out as the best performer, achieving 16.4%.
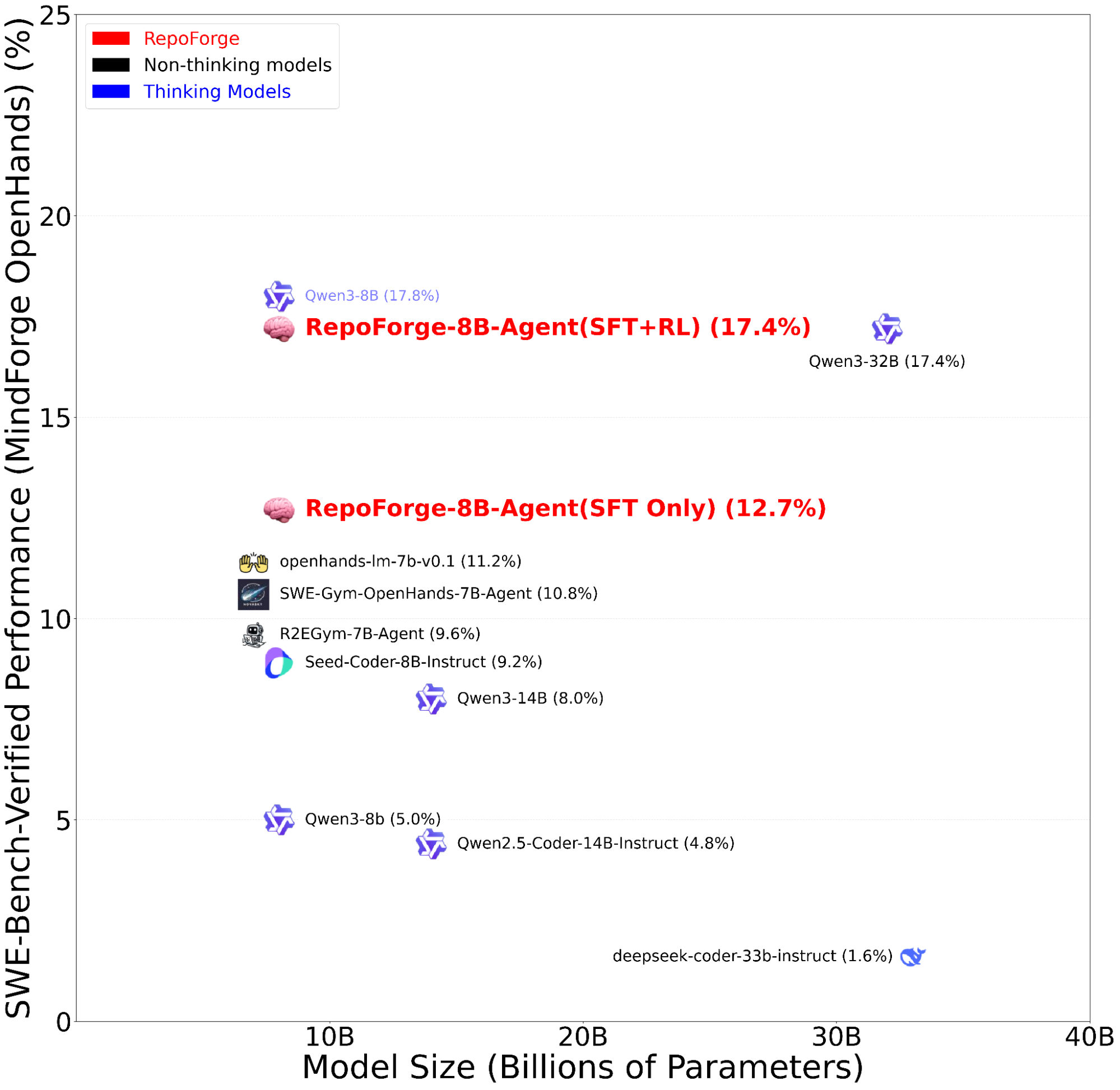
Figure 2: SWE-Bench Verified Performance vs. Model Size for LLM Coding Agents with RepoForge Harness tested in-house with RepoForge OpenHands (Our improved OpenHands). RepoForge-8B-Agent, a non-thinking model, achieves 17.4%, nearly matching the highest performing model in 8B scale.
The last twelve months have seen language models evolve from passive inferrers into active agents (i.e. RAGEN 11, Verl 10, ROLL 8, ART 9, SkyRL 5). Early open‑source frameworks such as Search‑R1 7 and MMSearch‑R1 8 taught models to interleave chain‑of‑thought with single tool invocations for web search. ToRL 9 pushed further by scaling reinforcement learning directly from base checkpoints with unrestricted exploration, while the underlying library veRL 10 supplied fast, efficient RLHF(Reinforcement Learning from Human Feedback) primitives. Most recently, SkyRL 5 demonstrated that the same ideas can be extended to long‑horizon environments like SWE‑Bench by layering VeRL with the OpenHands execution scaffold.
The pace of progress in agentic code LLMs has revolutionized software engineering, automating everything from pull request drafting to full module scaffolding. But moving from benchmark demos like SkyRL and OpenHands to real-world deployment uncovers bottlenecks at every stage. The heart of these benchmarks is an evaluation harness that must spin up isolated Docker environments, install dependencies, apply patches, run tests and record pass/fail results—essentially an automated CI/CD system that validates each proposed fix through real code execution.
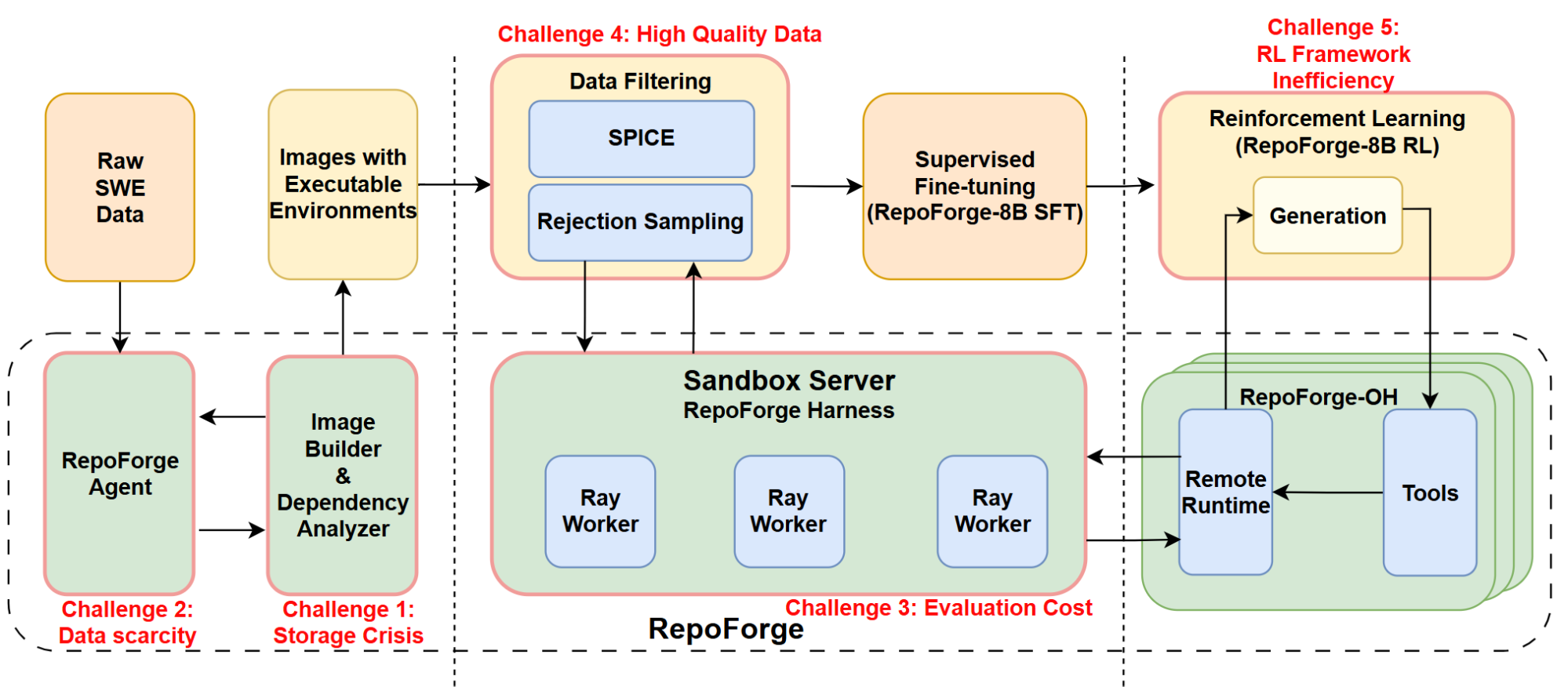
Figure 3: This diagram illustrates the RepoForge pipeline, designed to address key challenges in training and evaluating reinforcement learning (RL) agents for software engineering tasks.
However, building production-scale SWE agents requires addressing challenges that extend far beyond just the evaluation harness, touching every aspect of the training pipeline:
- Challenge 1: High Storage Costs of Container-Based Sandbox Evaluation - Evaluating software engineering tasks typically requires isolating each task within dedicated Docker images (~1.4 GB per image, plus approximately 7 GB per running container). This leads to significant disk usage, especially pronounced during reinforcement learning processes, which frequently execute tasks in multiple parallel rollouts over numerous training iterations. For example, evaluating merely 500 SWE-Bench Verified-like tasks demands around 690 GB of storage, easily exceeding 1 TB as RL evaluation scales up with repeated task execution, where each task requires a separate running container.
- Challenge 2: Inefficient and Sequential Reward Evaluation Pipelines - Existing evaluation framework harnesses use sequential, blocking pipelines with no artifact reuse, creating massive latency and wasted compute during training loops.
- Challenge 3: Limited Availability of High-Quality SWE Training Data - Executable SWE training data is scarce and typically requires extensive manual effort for curation, especially for historical issues. Developers must painstakingly reconstruct and validate dependencies to ensure accurate reproduction of issue-resolution processes.
- Challenge 4: High Cost and Subjectivity of Manual Data Labelling - Manual difficulty assessment and quality filtering are expensive, subjective, and don't scale. Expert annotation can cost $15,000+ per 1,000 instances.
- Challenge 5: Agentic Multi-Turn Reinforcement Learning Pipeline Bottlenecks - Multi-turn reinforcement learning suffers from "pipeline bubbles" where stages stall, especially problematic for 20-50 iteration trajectories required by modern scaffolds.
RepoForge tackles all of these with a fully autonomous, end-to-end pipeline. By combining Lineage Image Reuse and Runtime Environment De-bloating, it cuts per-task storage 14× (from 1.4 GB down to 0.102 GB). A Ray-powered, streaming evaluation harness drives over 70% latency reduction. The RepoForge Foundry autonomously generates 7,304 validated environments from real GitHub commits with zero manual work. SPICE automates labelling at 19,000× lower monetary cost than human annotation. Asynchronous Docker execution eliminates pipeline bubbles and delivers a 3× RL speedup. Altogether, these innovations enable RepoForge-8B-Agent which is trained based on Qwen3-8B to reach 17.4% on SWE-Bench Verified, setting a new state of the art for models under 8B parameters.
We also share key lessons learned about data quality, training strategies, and the unique challenges of scaling small models for software engineering tasks.
Challenges
Challenge 1: High Storage Costs of Container-Based Sandbox Evaluation
In many existing SWE evaluation setups, each task is isolated in its own Docker image for reproducibility and safety. However, a typical image averages about 1.4 GB. When scaled to hundreds or thousands of tasks, the required storage grows quickly and can overwhelm normal infrastructure.
Prior work highlights how costly containerized environments can be: for example, SkyRL reports that each running environment may consume over one CPU and around 7 GB of storage, while a similar RL framework, rLLM, requires roughly 6 TB of disk space to store thousands of images 24. Even a moderate setup, such as 16 tasks with 8 rollouts each, can use over 100 CPUs and nearly 1 TB of disk space. Running just 500 SWE‑Bench‑Verified tasks already needs about 700 GB. Scaling to RepoForge’s 7,304 tasks would exceed 10 TB if the same approach were used.
The problem gets worse with reinforcement learning and rejection sampling, where many containers run in parallel. For example, 128 concurrent tasks at 7 GB each need around 896 GB just for runtime. Running all 7,304 tasks with both base and runtime images would require around 61 TB, far beyond typical hardware.
When storage becomes the bottleneck, CPUs sit idle waiting for disk resources, severely limiting training speed and efficiency.
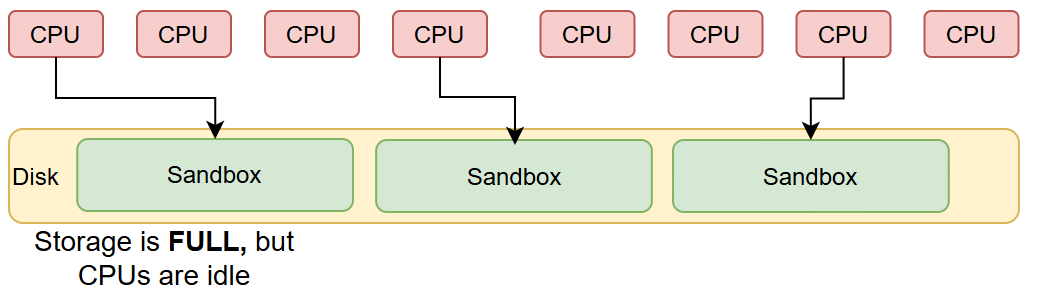
Figure 4: In real training scenarios, the worker concurrency is highly constrained by disk utilization.
Challenge 2: Inefficient and Sequential Reward Evaluation Pipelines
Execution feedback is critical for training software engineering agents because, unlike typical NLP tasks scored with static metrics, their outputs must actually run in real environments. A patch is only correct if it compiles, passes all tests, and leaves existing functionality intact. This requirement for real execution creates unique infrastructure demands.
Existing systems like SWE‑Bench and SWE‑Gym handle this with sequential, blocking pipelines. Each task must fully finish building its Docker environment, then install dependencies, and only then run evaluations. There is no overlap between these stages and no reuse of prior work. Managing dependencies becomes complex (1,452‑line configuration file), often involving massive configuration files and separate Docker images for each instance. Because every instance reinstalls its dependencies from scratch, resources are wasted as CPUs and memory remain idle during blocking I/O.
These problems worsen when scaling up for reinforcement learning. RL requires frequent reward calculations, but sequential evaluation causes each instance to take 2 to 10 minutes, so multi‑turn training with 20–50 iterations can stretch into days.
The engineering challenge is that repositories vary widely in languages and dependencies, each must run in an isolated environment, results must be reproducible, network calls can slow down installs, and large‑scale RL needs hundreds of evaluations per hour. Traditional frameworks, designed for simpler static benchmarks, cannot handle this dynamic and resource‑intensive execution at scale.
Challenge 3: Limited Availability of High-Quality SWE Training Data
High‑quality, executable SWE training data is very limited. Most public benchmarks only offer a few hundred tasks that are static, outdated, and built for one‑time evaluation rather than large‑scale training. They depend heavily on manual environment setup and human labelling, which is slow, costly, and difficult to scale.
For teams training LLMs for software engineering, this scarcity causes serious problems. There aren’t enough varied tasks to teach models real‑world challenges, annotations are inconsistent and subjective, and it can take months of manual work just to collect a few thousand usable examples. This leads to stalled training pipelines, models that plateau, and high costs that block scaling.
Existing systems highlight this challenge. SWE‑bench uses manual Dockerfile setups for 500 tasks, requiring heavy labour and often leading to compatibility issues. SWE‑gym spent over 200 hours building about 2,400 tasks, still fully manual and not scalable. Skywork‑SWE adds some automation with a three‑tier Docker hierarchy, but still needs manual configuration templates. SWE‑bench Live relies on an LLM agent to set up environments, but it doesn’t learn from previous attempts. SWE‑factory uses multiple agents with memory pooling, but remains complex and still needs manual checks. These approaches show how difficult it has been to create large, reliable SWE datasets.
Challenge 4: High Cost and Subjectivity of Manual Data Labelling
Labelling SWE training data is a major bottleneck because it demands expert judgment on problem clarity, test validity, and fix difficulty. OpenAI’s SWE-bench Verified addressed this by manually filtering 500 high-quality examples from over 12,000 candidates. On this curated set, GPT-4o achieved a 33.2% pass rate, more than doubling prior open-source results.
Each SWE-bench Verified task had to meet three strict criteria: the issue statement had to be unambiguous, tests had to cover all valid solutions without rejecting correct fixes, and an experienced engineer should be able to implement the patch in under an hour. Reaching these standards required months of human review and cost thousands of dollars per thousand labels.
Unlike simpler NLP annotations, SWE labelling involves deep repository exploration—tracing dependencies across multiple files, interpreting build and test pipelines, and actually running patches to confirm correctness. Reinforcement-learning pipelines demand tens of thousands of such labelled instances, making manual annotation economically and practically impossible. Continuous changes in real-world codebases only add to the challenge, as labels can become outdated with dependency updates, requiring ongoing re-labelling.
Challenge 5: Agentic Multi-Turn Reinforcement Learning Pipeline Bottlenecks
Multi‑turn reinforcement learning at the repository level relies on three stages: the model generates actions, interacts with an environment, and receives rewards. Scaling this to 20–50 iterations per trajectory, as required by the OpenHands scaffold, makes it difficult to keep the system efficient, stable, and well‑utilized. The following key bottlenecks impose significant challenges, making RL prohibitively expensive.
Resource management. Frameworks like SkyRL‑OpenHands use a two‑stage Docker build that adds an internal server layer, bloating each image by 4–10 GB and quickly consuming disk space. Others, like R2EGym, lack distributed training support, so every machine must store full images, adding an immense storage demand .
Pipeline bubbles. Multi‑container workflows over many iterations create overhead and idle time. Model generation and environment execution rely on different resources, and if there are too few rollout requests or too few concurrent executions, CPUs sit idle. Latency from network calls, image builds, and I/O adds to the delay. Worse yet, the pipeline often waits for all trajectories in a batch to finish; if one task takes much longer than the others, it creates a long‑tail delay that stalls every worker and reduces overall throughput and utilization.
Our Method
Challenge 1 Solution – Storage‑Efficient Lineage Image Reuse & Runtime Environment De-bloating to Reduce Disk Usage
To address this issue, we implement two key optimizations, Lineage Image Reuse based on dependency and Runtime Environment De-bloating
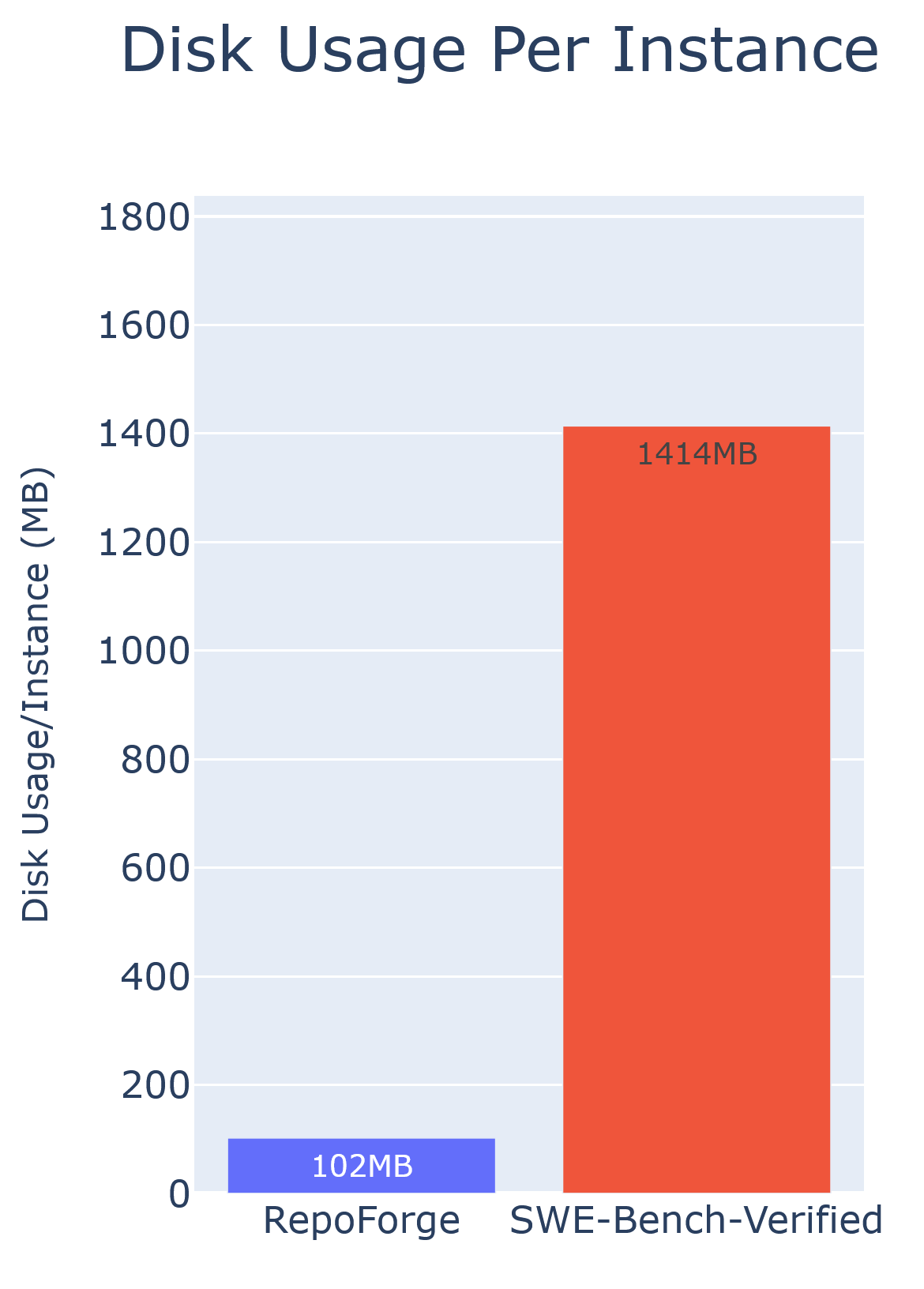
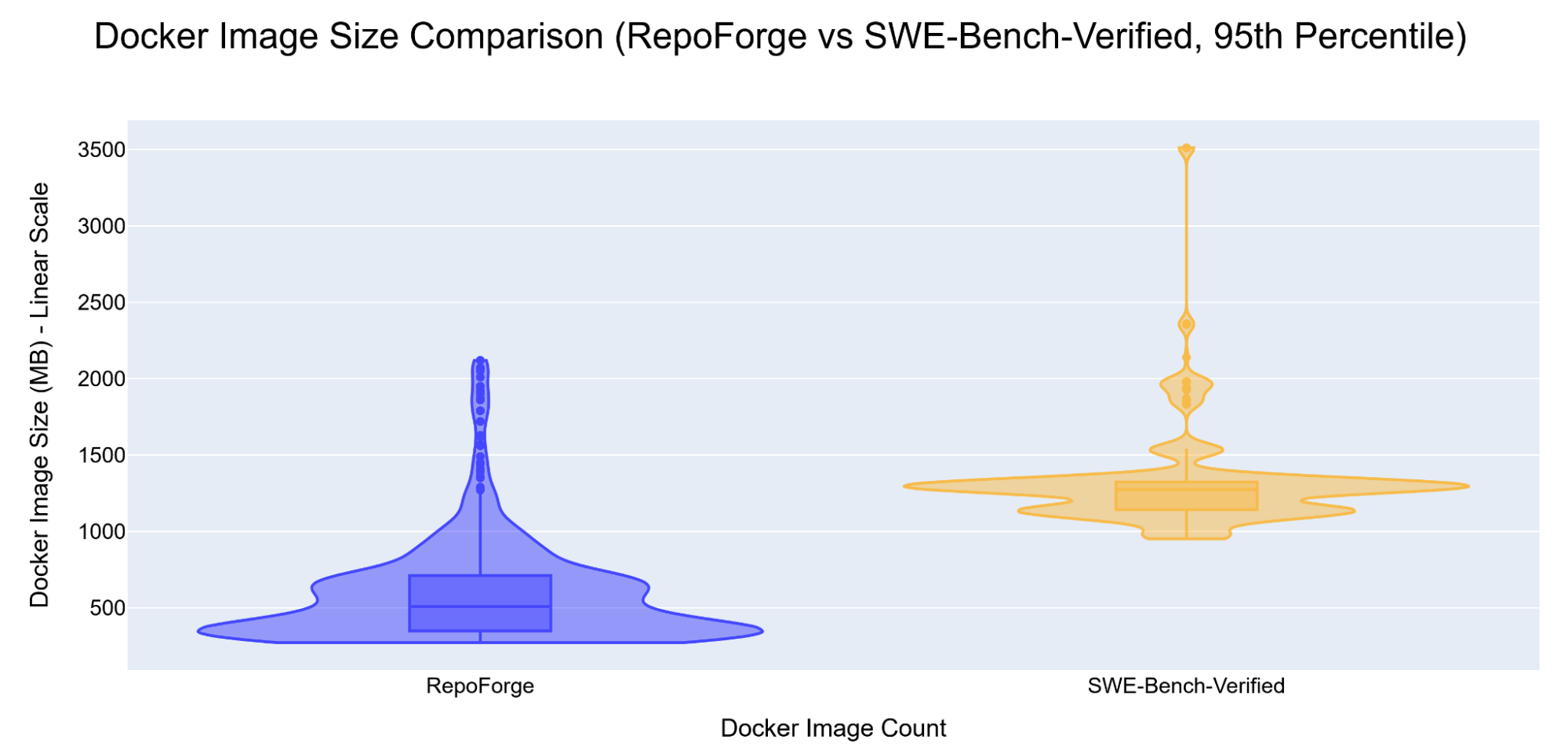
Figure 5: Disk usage per instance in the RepoForge framework versus SWE‑Bench‑Verified. Left: Per Instance, Right: Single Image size distribution
Lineage image reuse: RepoForge uses an automatic process called Lineage image reuse. This process looks at all the Docker images and finds shared dependencies between them. When two images share enough in common and all tests still pass, one image can be rebased to reuse the other instead of keeping its own copy. A custom algorithm goes through all instances and keeps trying to merge them with earlier or later images until no more merges are possible. With this method, thousands of tasks that would normally need thousands of heavy images can instead share a much smaller number of optimized images.
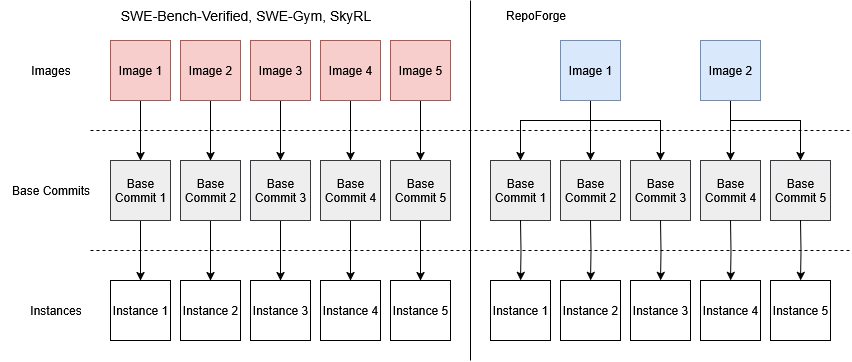
Figure 6: In RepoForge Framework, multiple base commits can work on the same image, greatly reducing the disk requirement.
Runtime Environment De-bloating: On top of that, RepoForge builds Minimal Runtime Environments. Instead of using large base images like full Ubuntu builds, it starts with very slim images and only installs exactly what is needed for each task. Any unnecessary packages, compilers, or tools (i.e., bloat) are removed. This cuts down the size of each image dramatically.
With these two methods combined, the average image size per instance drops from 1.4 GB to just 102 MB. In total, 7,304 tasks only require 937 optimized images, with each image reused across multiple tasks. This means less disk space is used, CPU resources are no longer idle waiting on storage, and the whole training pipeline runs much faster and more efficiently.
Challenge 2 Solution – RepoForge Harness - A Ray-Powered Distributed Efficient Evaluation Engine
To improve the efficiency of evaluating rewards from code execution feedback, we built RepoForge Harness, with the inspiration of the SWE‑Bench evaluation harness. RepoForge Harness is fully distributed (based on Ray) and supports streaming, overlapping stages while reusing build artifacts across task instances, achieving 10x build speedup and 3x evaluation speedup.
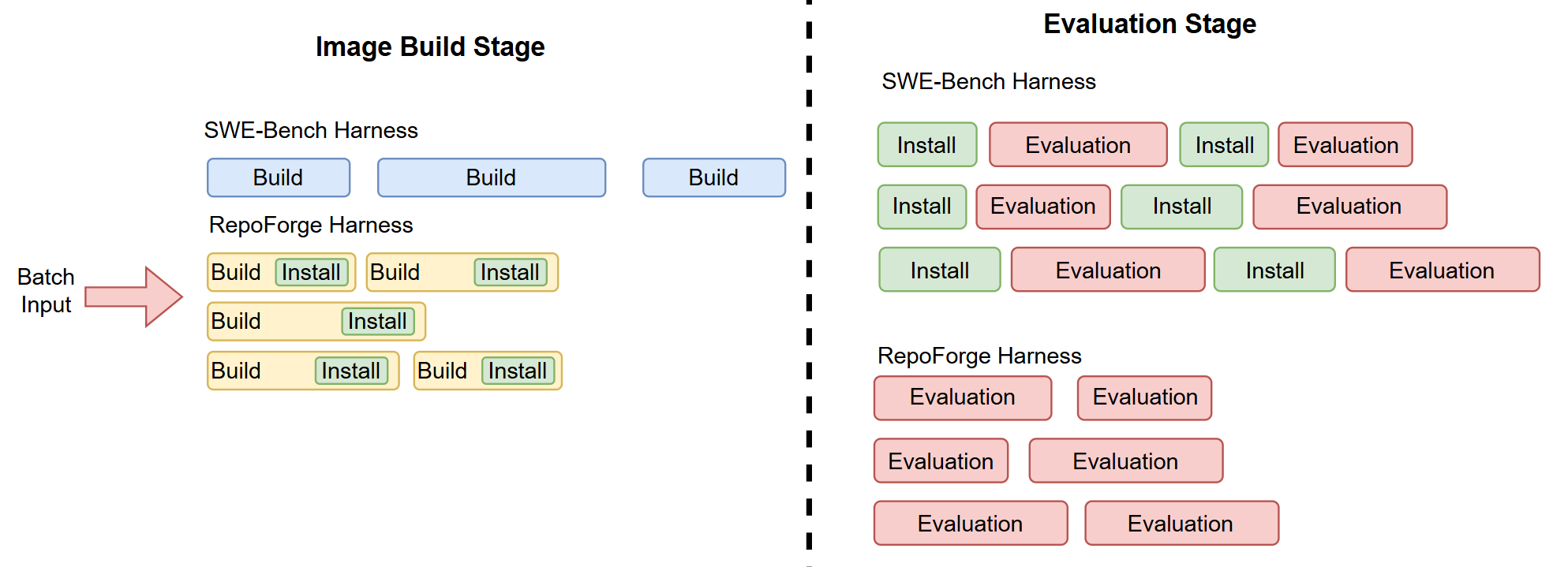
Figure 7: In the default SWE‑Bench harness, container images are built one at a time, in a strictly sequential manner. During evaluation, RepoForge pre‑installs all required runtime dependencies for each unique task instance so the evaluation can run immediately.
One key improvement is that RepoForge Harness enables a parallel, streaming style build pipeline. Instead of blocking on a single image, RepoForge builds many images at the same time using aiodocker. In addition, dependencies are installed during the build stage, so evaluation starts immediately without extra network calls or repeated installs. This is very efficient especially when the training environment is behind a corporate network wall.
Another improvement is Ray‑powered distributed execution. Instead of handling everything on one local machine, RepoForge uses Ray actors to start sandboxes on multiple machines at once. Each actor can reuse shared container images, so the system avoids redundant builds and handles task instances in parallel.
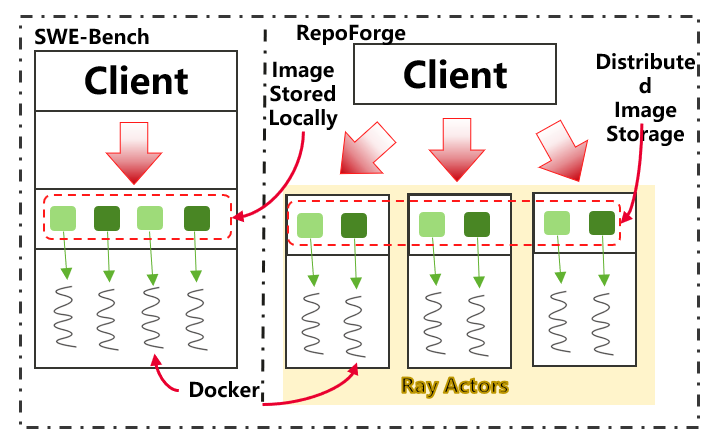
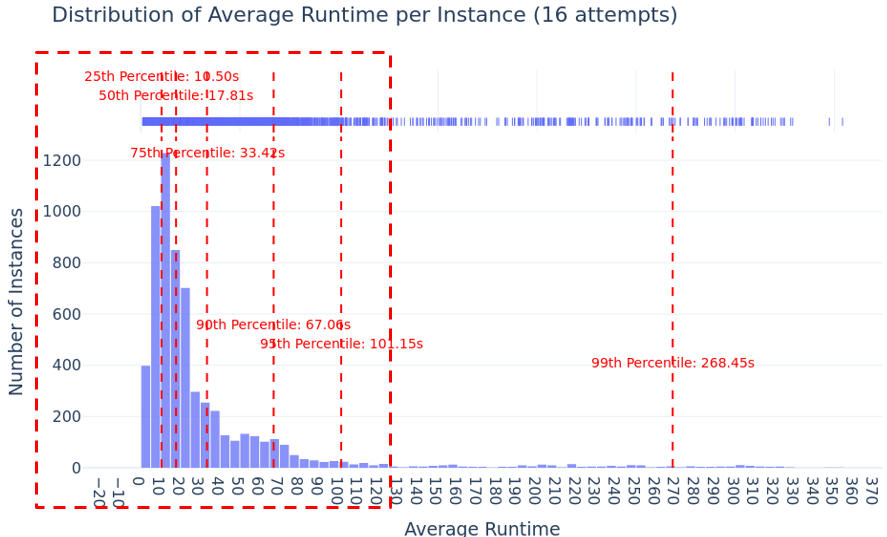
Figure 8(Left): RepoForge leverages Ray Actors to scale up the sandbox server across multiple nodes.
Figure 9(Right): Averaged over 16 runs, RepoForge instance evaluations remain consistently fast, over 96% complete within two minutes.
In tests, over 96 percent of evaluations finish within two minutes, with a hard cap of 120 seconds. Average evaluation time drops from 2–10 minutes in the old system to about 75 seconds. The system can scale up to 64 workers, supports automatic pooling and intelligent caching, and works across multiple programming languages like Python and C++ without special setup.
RepoForge Harness natively supports multi‑language repositories — Python, C, C++, and more.
Table 1: Comparison of SWE-Gym Harness system vs RepoForge Harness
| Feature | SWE-Gym | RepoForge |
|---|---|---|
| Architecture | Centralized/ Single NodeSequential | Distributed (Ray) |
| Concurrency | Single-threaded Sequential | Up to 64 workers |
| Image Reuse | None | Intelligent caching |
| Container Management | Manual | Automatic pooling |
| Install Timing | After build | During build |
| Execution Model | Blocking | Fully Asynchronous |
| Image Build Time (Mean) | 537s | 58s (-89.2%) |
| Evaluation Time (Mean) | 56s | 17s (-69.6%) |
| Multi-Language Support | No | Yes |
Challenge 3 Solution – RepoForge Foundry: Fully Autonomous at Scale for Real-World SWE Challenges:
To break through the data wall, we built RepoForge Foundry— a fully autonomous system that creates evaluation-ready SWE environments with minimal human intervention.
Table 2: Comparison of existing SWE environment‑generation systems vs RepoForge Foundry.
| System | Manual Work | Scale (Unique Problem Statements/instances) | Docker Optimization | Validation | Learning | Evaluation‑ready |
|---|---|---|---|---|---|---|
| SWE-bench | 100% Manual | 500 instances | None | Human | None | Yes |
| SWE-gym | 200+ hrs manual | 2.4K instances | None | Human | None | Yes |
| Skywork-SWE | Template creation | 10K instances | Basic hierarchy | Semi-auto | None | Yes |
| SWE-Builder | Manual verification | Unknown | None | Mixed | Memory pool | Yes |
| Repo2Run | 0% Manual | 420 instances | None | Fully automated | None | No |
| RepoForge Foundry | 0% Manual | 7.3K instances | 937 optimized images | Fully automated | Self-improving | Yes |
Evaluation‑ready only if it correctly runs the designated FAIL_TO_PASS and PASS_TO_PASS tests both before and after applying the golden patch, ensuring meaningful evaluation. Repo2Run only checks that pytest runs, so its images aren’t reliable.
Instead of relying on a small, hand-labelled benchmark, RepoForge Foundry actively explores real‑world GitHub commits, reconstructs their build and test environments, and validates them into rich, executable tasks — all without human intervention.
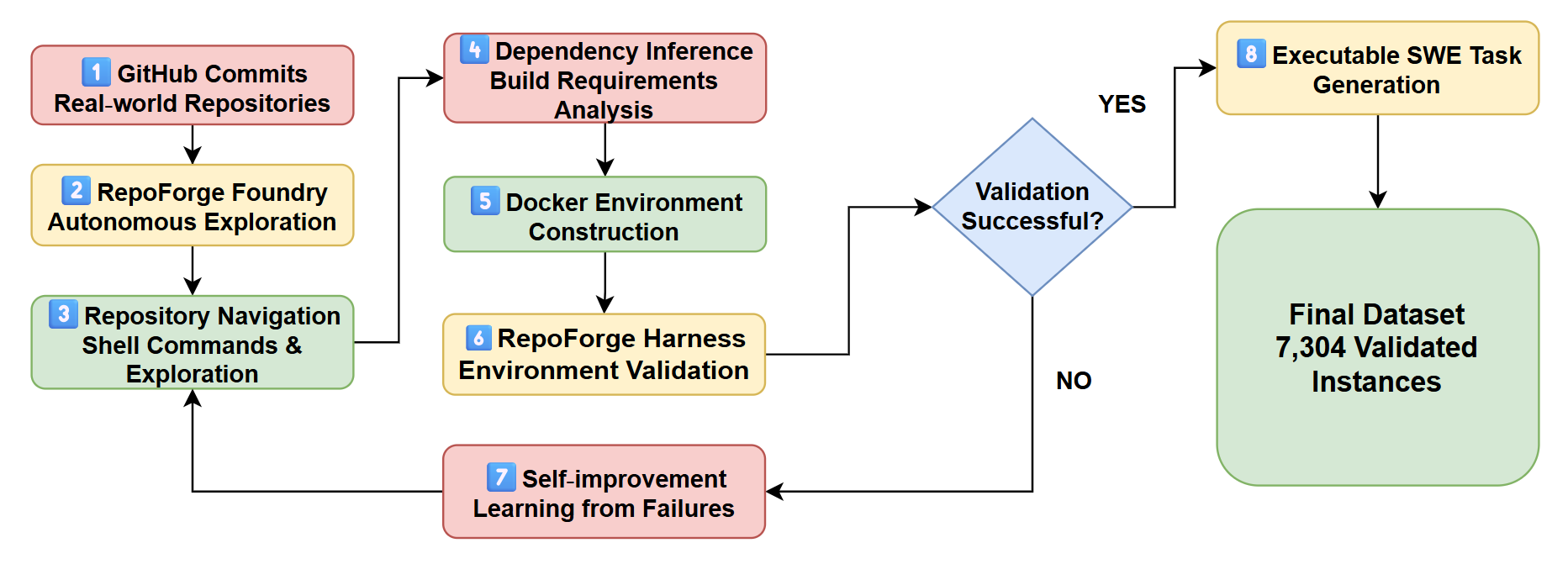
Figure 10: Overview of the RepoForge automated pipeline for dependency inference, Docker environment construction, validation, self‑improvement, and SWE task generation.
RepoForge Foundry leverages a multi‑agent ReAct framework to autonomously ingest real‑world GitHub repositories and issues, infer their full build graph, and generate optimized, isolated Docker environments. Then, RepoForge Harness (described in the solution of Challenge 2) validates each image with end‑to‑end FAIL_TO_PASS and PASS_TO_PASS tests and automatically rolls back and learns from any failures. For a detailed workflow, see Figure 12.
We end up with an automated SWE environment construction pipeline that supports multiple programming languages and hybrid build systems, guarantees test correctness by actually executing tests. By reducing manual efforts, RepoForge Foundry enables SWE data as a renewable fuel for training.
The result is 7,304 fully validated and annotated SWE task instances generated automatically, powered by only 937 optimized Docker images with built-in reuse. Furthermore, we are able to label rich information on these instances at a cost much lower than manual curation.
Challenge 4 Solution – SPICE: Automated Difficulty Assessment at Scale
Our SPICE 23 (Structured Problem Instance Classification Engine) eliminates the manual labelling bottleneck by automatically evaluating task difficulty and quality across four dimensions: code complexity, repository structure, test coverage, and solution patterns. It then assigns objective difficulty scores based on quantitative metrics, filters for high‑value instances, and continuously refines its assessments using model performance data at a tiny fraction of the cost of human annotation.
Key innovations in SPICE include its reliance on concrete code analysis instead of subjective judgment, a fully automated difficulty‑scoring pipeline, and a scalable architecture that applies consistent criteria across thousands of instances. This approach delivers uniform, reliable labelling at scale and reduces annotation costs significantly compared to traditional manual methods.
With SPICE, we automatically labelled and difficulty‑assessed over 7,000 instances, achieved a 19,000× cost reduction compared to manual labelling while maintaining 87.3% accuracy on issue clarity and 68.5% on test coverage, and enabled rapid iteration for new datasets.
Challenge 5 Solution – RepoForge-OpenHands Scaffold
To address challenge 5, we introduced the RepoForge-OpenHands scaffold, which inherits most of the original OpenHands scaffold features and implements four additional engineering optimizations. As a result, we achieved a 3x speedup, making it more suitable for long-horizon agentic RL training.
Direct Docker Exec Integration: RepoForge‑OpenHands mounts its OpenHands-styled Python tools into containers and the runtime invokes them via docker exec, removing the embedded server and second build stage (4 - 10 GB per image and additional build time) by back‑porting OpenHands utilities to Python 3.5, yielding a ~5× speedup and slashing disk usage by 80% during the training.
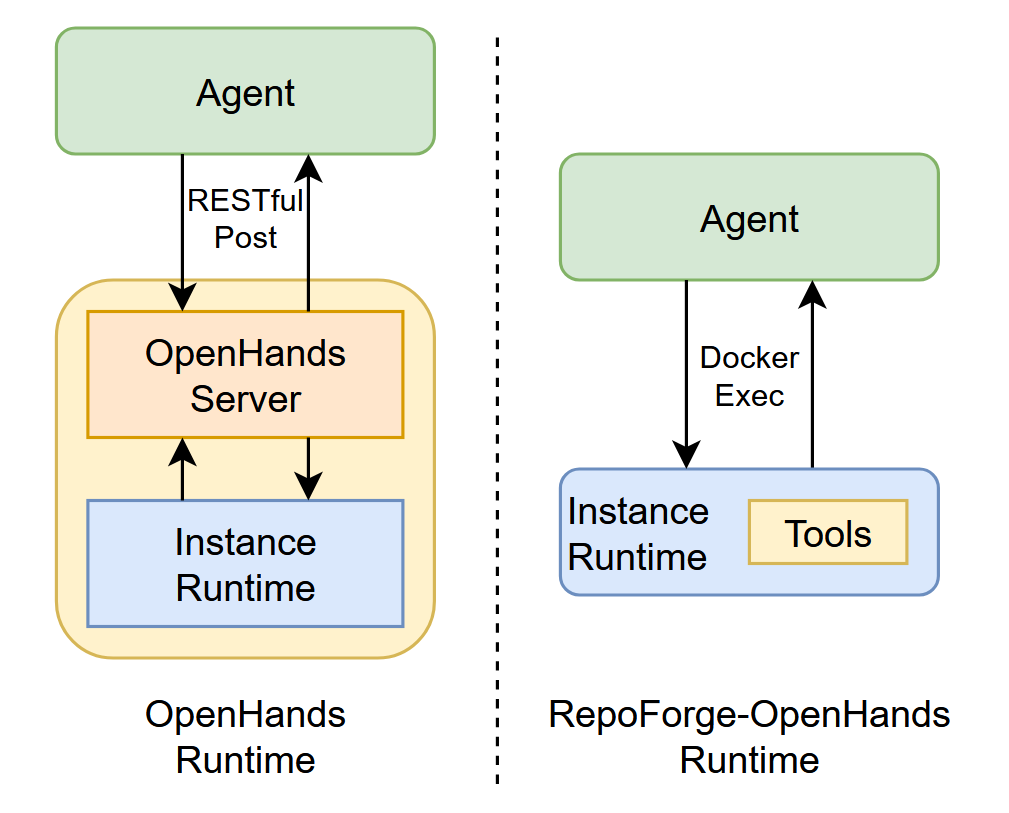
Figure 11: Comparison of the OpenHands server–based runtime versus the Docker‐exec–based RepoForge‑OpenHands runtime architectures.
Remote Sandbox Server: We decouple environment execution from training with a Ray‑managed remote sandbox that runs two concurrent pipelines of up to 32 agents each, ~80–100 isolated containers per host, enabling scalable, parallel isolation without impacting the training process.
Fully Asynchronous I/O: By replacing Docker’s blocking HTTP client calls with non‑blocking libraries (aiodocker, aiohttp), we eliminate GIL‑induced serialization, achieve true parallelism in environment dispatch, and significantly reduce I/O overhead under high concurrency.
Dynamic Producer–Consumer Rollout: Leveraging Ray’s worker queue model, we created a producer-consumer model, where the workers dynamically poll (instance, trajectory) pairs instead of fixed subsets, eradicating long‑tail stalls in balanced batching and delivering a 1.4× speedup on representative test batches.
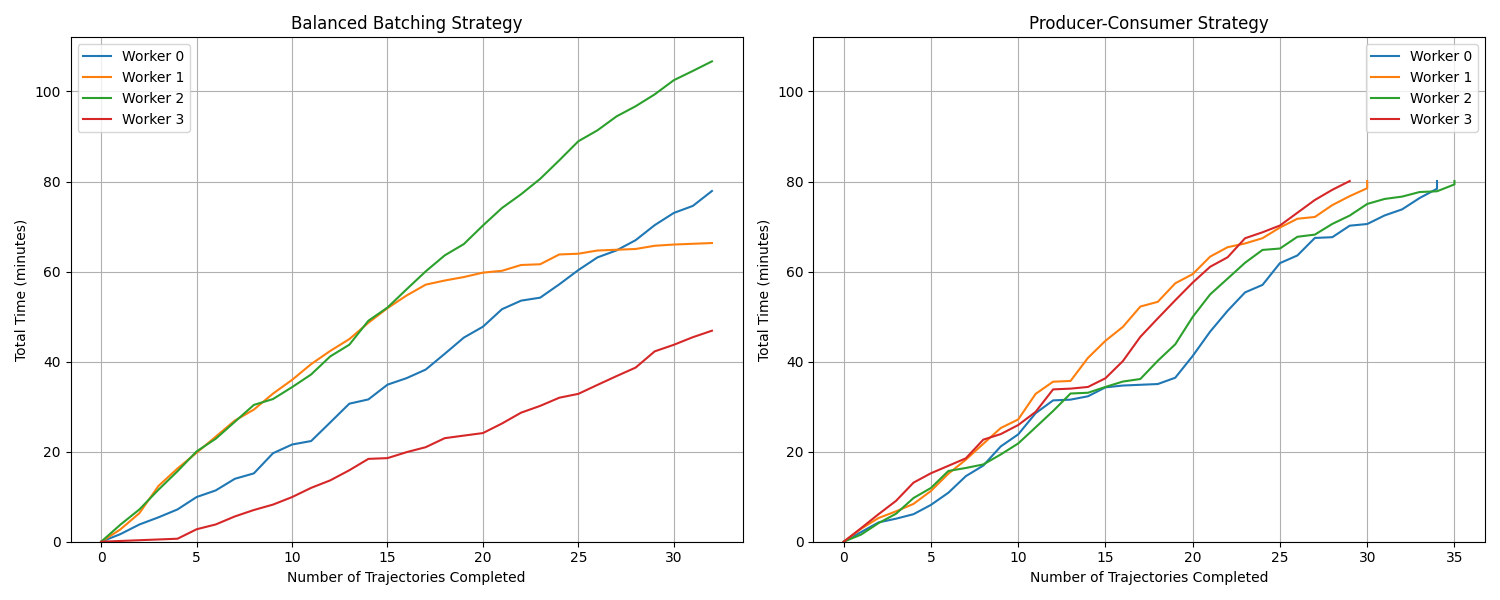
Figure 12: Comparison of rollout distribution strategies - Balanced Batching vs. Producer-consumer on RepoForge-OpenHands scaffold.
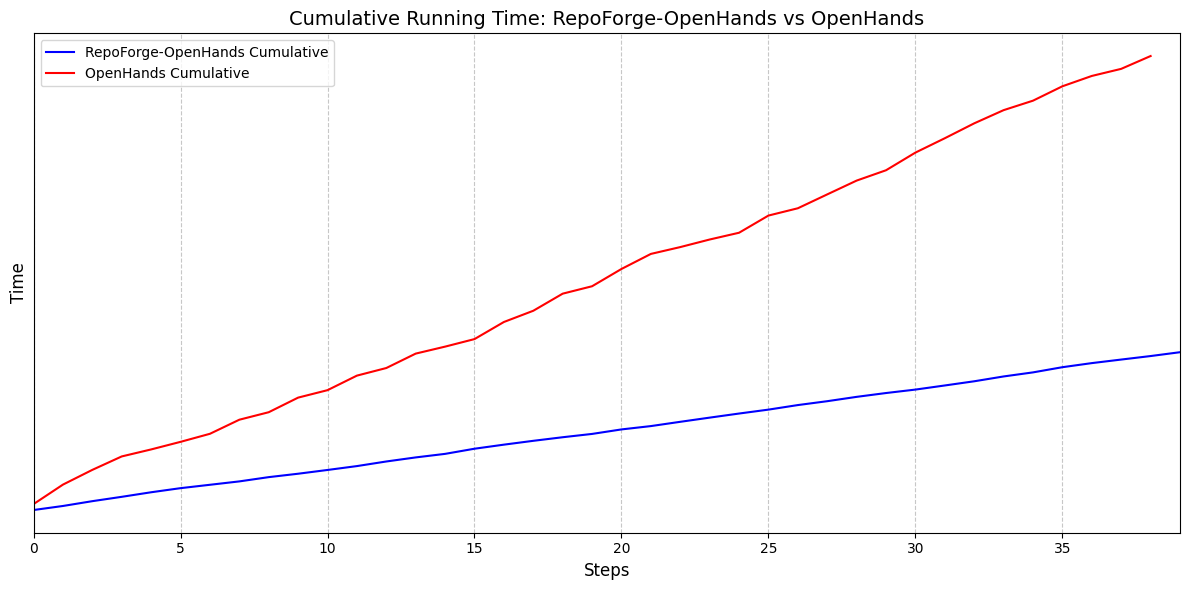
Figure 13: Comparison of running times - OpenHands Scaffold vs. RepoForge-OpenHands Scaffold on 40 training steps with the same dataset (not including build).
After applying the above optimization, the results in Figure 15 show a 3× end‑to‑end speedup compared with the vanilla OpenHands, a 5× faster tool invocation with over 80% storage reduction, and a 1.4× throughput gain by smoothing idle time and improving resource use on long‑tail batches.
Training Recipe
Supervised Fine-Tuning (SFT)
With over 7,304 executable environments, the next challenge was ensuring data quality. Quantity was no longer a problem, but we needed tasks that were well‑specified, properly tested, and of manageable difficulty.
First, we used SPICE to score each raw instance on clarity, test validity, and difficulty. Instances scoring 1 or lower on all three metrics were kept, removing ambiguous, poorly tested, or overly complex tasks. This produced a pool of clean, reliable tasks.
Next, we performed rejection sampling with OpenHands‑32B-Agent under the RepoForge Harness. For each filtered instance, the agent generated up to eight patches. Each patch was applied and immediately tested. Only patches that met both PASS_TO_PASS and FAIL_TO_PASS criteria were kept. To avoid overfitting and hallucination of instance-specific constants (such as file directory paths), every run used a randomized working directory and an isolated container.
This process produced 1,202 high-quality instances, each with a complete multi-turn trajectory, SPICE metadata, and validated test suites. These were used to fine‑tune RepoForge-8B-Agent over one epoch, creating a strong starting point for reinforcement learning.
Reinforcement Learning (RL)
For RL, we built on this SFT model using the RepoForge‑OpenHands scaffold with CodeAct and AsyncRollout. The model used three core tools: execute_bash to run shell commands, str_replace_editor to edit files, and finish to end a trajectory. Rewards were simple and binary—1 if all unit tests passed, 0 otherwise.
Training used a curated dataset of 160 instances that the teacher model had already solved during SFT. This ensured the model started with tasks it understood, allowing RL to focus on refining behaviour rather than learning from scratch. We trained for 40 steps over two epochs with a temperature of 0.5, a KL‑divergence coefficient of 0.001, and a cap of 35 iterations per trajectory.
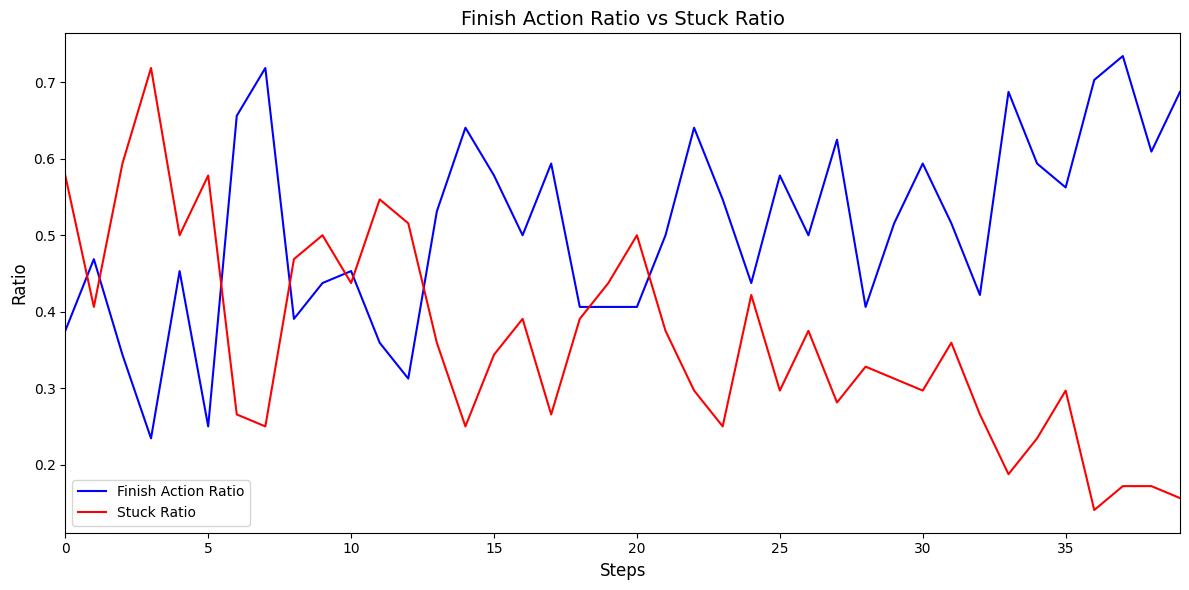
Figure 14: Action finish ratio and stuck ratio during the training.
Evaluation
We evaluate RepoForge-8B‑Agent on both the RepoForge‑OpenHands and the official OpenHands frameworks, summarizing resolve rates on SWE‑Bench‑Verified instances across various models and configurations. A successfully resolved instance means the Agent model generated and applied a code patch, with all the unit tests corresponding to the problem statement having been run and passed. In Table 3, the “RepoForge-OpenHands” column displays SWEBench-Verified resolve rate performance using our RepoForge harness, “OpenHands” column displays resolve rate using OpenHands release version 0.32, and “Reported” are taken from figures published in the original papers [cite]. The “Thinking” column denotes whether a model employs explicit reasoning (e.g., chain‑of‑thought or scratchpad) or runs without such reasoning, which means i) the model does not natively support outputting reasoning content or ii) it has been disabled via the chat template.
Table 3: Performance comparison of RepoForge-8B‑Agent against prior coding agents.
| Model | RepoForge-OpenHands% | OpenHands% | Reported % | Thinking |
|---|---|---|---|---|
| RepoForge-8B-Agent(SFT+RL) | 17.4 | 16.4 | / | No |
| RepoForge-8B-Agent(SFT Only) | 12.7 | 10.5 | / | No |
| R2EGym-7B-Agent 19 | 9.6 | 10.2 | 19 | No |
| Qwen3-8B (Non-thinking) | 5 | 4.2 | / | No |
| Seed-Coder-8B-Instruct 20 | 9.2 | 4.6 | 11.2 | No |
| SWE-Gym-OpenHands-7B-Agent | 10.8 | 11.4 | 14.6 | No |
| all-hands/openhands-lm-7b-v0.1 | 11.2 | 15.4 | 10.6 | No |
| Qwen2.5-Coder-14B-Instruct | 4.8 | 3.2 | / | No |
| Qwen3-32B(non-thinking) | 17.4 | 9 | / | No |
| Qwen3-14B(non-thinking) | 8 | 3 | / | No |
| deepseek-ai/deepseek-coder-33b-instruct | 1.6 | 1.6 | / | No |
| DeepCoder-14B-Preview 21 | 8 | 6.6 | / | Yes |
| Qwen3-8B | 17.8 | 11.4 | / | Yes |
| Qwen3-32B | / | 23% | / | Yes |
| QwQ-32B | / | 18.8% | / | Yes |
Reported results are taken directly from the respective papers or model cards of prior work. OpenHands% and RepoForge‑OpenHands% are our own measurements from running each model under the corresponding harness. To ensure fairness and stability, we reran every evaluation multiple times and confirmed that the results remained consistent within small variance ranges.
RepoForge-8B‑Agent(SFT+RL) achieves 17.4% on RepoForge‑OpenHands and 16.4% on OpenHands, setting a new SOTA among ≤8B models, even though it does not use reasoning steps. RL adds significant performance gains: SFT‑only training plateaued at 12.7% on RepoForge‑OpenHands, while combining SFT with RL pushed accuracy to 17.4%. RepoForge-8B-Agent matches or surpasses several 14B–32B‑scale models, proving that small models can punch well above their weight.
Lessons Learnt
From our experiments with RepoForge-8B‑Agent, we learned a few key lessons that shaped our design.
Data quality matters far more than quantity. Randomly sampled environments gave only 3.0% accuracy after SFT, while SPICE‑filtered high‑quality data reached 12.7%, a 4.2× improvement. In RL, random data gave 6.5% while filtered data reached 7.8%. Automated filtering like SPICE and rejection sampling greatly improves both SFT and RL results.
A supervised fine‑tuning warm start is essential for RL. Running RL directly on the base model only reached 7.8% accuracy, but adding a brief SFT stage boosted it to 17.4%. SFT lets the model succeed on some tasks early, providing useful rewards for RL to build on.
Small models overfit easily. Using too much SFT data hurt performance, with accuracy peaking at 12.7% on 1,000 trajectories but dropping to 10.7% on 2,000. Careful dataset sizing and regularization are important to avoid overfitting.
Conclusions and Looking Ahead
By unifying storage‑efficient sandboxing, a Ray‑powered evaluation harness, automated data generation, SPICE‑based labelling, and a bubble‑free RL scaffold, we have shown that even ≤8B models can reach new state‑of‑the‑art performance on demanding benchmarks like SWE‑Bench‑Verified.
Looking ahead, we are extending RepoForge to support broader language ecosystems, integrating multi‑agent planning for long‑horizon tasks, and exploring continuous learning loops where deployed agents feed back fresh, validated data into the pipeline. Our vision is simple but ambitious: a self‑improving, always‑on platform that pushes the boundaries of autonomous software engineering every single day.
Major Contributors
- Core Contributors: Zhilong Chen and Chengzong Zhao
- Project Lead: Boyuan Chen and Dayi Lin
- Main Contributors: Yihao Chen, Arthur Leung, Gopi Krishnan Rajbahadur, Gustavo Oliva
- Advisor: Ahmed Hassan
We would also like to thank Haoxiang Zhang, Aadi Bhatia, Rui Shu, Kim Kisub, Alex Yang, Kirill Vasilevski, Youssef Esseddiq, Yanruo Yang, Chong Chun Yong for the data preparations.
Citation
If you find RepoForge useful to your research or projects, please consider citing it:
@misc{repoforge2025,
title = {RepoForge: Training a SOTA Fast-thinking SWE Agent with an End-to-End Data Curation Pipeline Synergizing SFT and RL at Scale},
author = {Zhilong Chen, Chengzong Zhao, Boyuan Chen, Dayi Lin, Yihao Chen,Arthur Leung, Gopi Krishnan Rajbahadur, Gustavo Oliva, Haoxiang Zhang, Aadi Bhatia, Rui Shu, Kim Kisub, Kirill Vasilevski, Youssef Esseddiq, Yanruo Yang, Ahmed Hassan},
year = {2025},
}
Reference
Footnotes
-
Ray: A distributed framework for emerging AI applications ↩ ↩2
-
Introducing OpenHands LM 32B -- A Strong, Open Coding Agent Model ↩
-
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning ↩ ↩2
-
verl: Volcano Engine Reinforcement Learning for LLMs ↩ ↩2 ↩3
-
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning ↩ ↩2
-
ROLL: Reinforcement Learning Optimization for Large-Scale Learning ↩
-
Training Software Engineering Agents and Verifiers with SWE-Gym ↩
-
Skywork-SWE: Unveiling Data Scaling Laws for Software Engineering in LLMs ↩
-
SWE-Factory: An Automatic Issue Resolution Dataset Construction Pipeline via LLM-based Multi Agents ↩
-
R2E-Gym Procedural Environment Generation and Hybrid Verifiers for Scaling Open-Weights SWE Agents ↩ ↩2
-
DeepCoder: A Fully Open-Source 14B Coder at O3-mini Level ↩ ↩2
-
SPICE : An Automated SWE-Bench Labeling Pipeline for Issue Clarity, Test Coverage, and Effort Estimation ↩ ↩2 ↩3