MindForge: Building Reproducible SWE-bench Environments at Scale
2026-05-26
Training a coding agent using reinforcement learning (RL) requires two things that are tedious to produce by hand: a runnable environment for GitHub repositories at specific commits containing bugs (“base commits”), and a script that says "the bug is fixed" with an exit code. MindForge agentically produces both from a SWE-bench-style instance and packages the result to enable seamless integration with SFT or RL pipelines.
This post describes what the project does, where it borrows from prior work, how the agents are wired together, and what it produced when we pointed it at ~3,900 Pull Request (PR) instances across four programming languages.
What is MindForge?
MindForge takes a SWE-bench instance — a repo, a base commit, and the Git diff from the original PR — and runs an “env build” job that outputs two artifacts:
- A Dockerfile that builds the bug-state environment from scratch.
- A verifier script whose exit code is the ground truth: zero when a correct fix is applied, non-zero otherwise.
Aside from the “env build” job, MindForge also adds two additional features:
- A Patch Agent that splits the original PR diff into a gold patch (production code) and a test patch (tests only), allowing the environment to be easily switched between pre-patch and post-patch states without leaking the fix into the test setup.
- A Harbor Converter that converts a validated instance to a Harbor task folder, ready to use in an agent benchmark or RL rollout.
The pipeline runs using a single CLI with four input modes: single-instance, JSONL batch, a sweep grouping instances by repo, and a database sweep that claims instances atomically allowing multiple workers to run in parallel.
Related work, differences, and what we borrowed
The "verifier script + Docker Image" recipe is most prominently featured in SWE-Universe 1 (Alibaba, 2026), which builds almost a million verifiable environments using exit codes as the language-agnostic interface. Additionally, several other projects attempt to solve similar problems as MindForge:
| System | Goal | Languages | Open-Source? | Notes |
|---|---|---|---|---|
| SWE-Universe 1 | ~1 million verifiable environments | 7+ | No | Snapshots containers via docker commit; LLM-only hacking check |
| DockSmith 2 (2026) | Dockerfile generation | Python | No | Bash syntax pre-check before build |
| SWE-Bench++ 3 (2025) | Anti-hacking benchmark | Python | Yes | History-safe checkout; richer evaluation patterns |
| Repo2Run 4 (ByteDance, 2025) | Dockerfile generation | Python | Yes | Persistent shell; ~500 repos |
| R2E 5 (UC Berkeley, ICML 2024) | Repo-to-environment | Python | Yes | Pre-built fat image; in-container RPC |
| ROCK 6 (Alibaba) | RL sandbox for SWE training | — | Yes | Agent runs natively inside the sandbox; SDK orchestrates from outside |
What we kept from these:
- Exit-code as the verifier contract, from SWE-Universe 1. Decoupling verification from per-language test-output parsing is the single most important simplification for multi-language coverage.
- A cheap syntax pre-check on the verifier, from DockSmith 2. Catching syntax errors before spinning up Docker results in significant time savings at scale.
- Adaptive per-language timeouts, from SWE-Universe 1. Rust gets a 2× multiplier, Go 1.5×, because compilation is not free.
- History-safe checkout, from SWE-Bench++ 3. We strip future refs before handing the repo to the agent preventing it from simply reading the fix off
git log. - LLM-based hacking detection on every submission, from SWE-Universe 1. A judge model reviews the verifier and rules on whether it genuinely executes code or just pattern-matches its way to an exit code.
- Agent inside, orchestrator outside, in spirit from ROCK 6. The orchestrator runs on the host, while the agent runs natively inside a sandbox container. This allows the agent's tool calls to stay native instead of being routed through remote-exec translation.
What's different:
- Dockerfile, not container snapshot. SWE-Universe 1 and R2E 5 snapshot the container state once everything works. We require the agent to produce a Dockerfile that builds from a clean base image and passes validation. The artifact is auditable and rebuildable on any host; the cost is the agent has to actually think about reproducibility instead of installing things until tests pass.
- Two-stage agent: Selector + Builder. A lightweight read-only agent picks the language and base image before the builder is even started. SWE-Universe 1 uses a single agent. We found the version-detection step was happy to live in its own container with no write tools, which keeps the builder context clean and shrinks the blast radius if version selection turns out wrong.
- Multi-language. We support Python, JavaScript, TypeScript, and Rust, with Go in the language config — different from the Python-only focus of DockSmith 2, Repo2Run 4, and R2E 5. We trade SWE-Universe's 1 million-scale ambition for tighter validation and a portable Dockerfile.
- A dedicated Patch Agent. SWE-Universe 1 assumes the (test, fix) split is done by an LLM as a preprocessing step. We treat the split as its own agentic task with its own validator, because the env build agent needs the test patch to be exactly the test changes and nothing else.
- A Harbor converter. Postprocessing stage that converts a validated instance into a runnable Harbor task folder, allowing the usage of the output in benchmarks without any further reshaping.
A longer side-by-side and the architecture-decision rationale (agent inside vs. outside the container, fat vs. slim exploration image, two-agent vs. single-agent) live in the related_works/ directory.
Architecture
Orchestrator
The orchestrator is the host-side process that owns container lifecycles, holds a shared repo cache, runs the MCP server, drives validation, and writes results. It runs many tasks concurrently. Each task is a small state machine, and the MCP server is a polling HTTP queue rather than a stdio stream because we have many agents calling into one server.
The repo cache does full clones once before materialising a per-task worktree at the requested commit. This is much faster than re-cloning for every instance, and is also where we enforce history-safe checkouts: future refs are stripped at materialisation time so the agent cannot read the fix out of the repo's own history.
The MCP server exposes a small set of tools — request a runtime switch, submit a result, give up — and a separate set for the patch flow. Agents poll for orchestrator decisions; the orchestrator polls for agent submissions. This split is what lets one orchestrator drive many concurrent containerized agents without an event-loop bottleneck.
Env Agent
The env agent runs in two stages, followed by a validation pipeline that lives entirely outside the agent's context.
Stage 1 — Selector. A lightweight read-only container is started, containing the repo at the base commit. The agent's only job is to figure out the language and version: it reads whatever manifest files the repo provides (Python, Node, Rust, and friends each have their own) and submits a runtime decision about which Builder base image to use. No installs, no writes. Upon submission, the orchestrator stops the selector container and loads the selected Builder base image.
Stage 2 — Builder. A full container based on the language-specific base image chosen by the selector agent. The agent installs dependencies, writes the verifier, self-validates by toggling between pre-patch and post-patch states, then writes the Dockerfile and submits. The Dockerfile is required to follow a mandatory template — base image, workdir, copy, install, command — so a cheap structural check can verify it in milliseconds.
Stage 3 — Orchestrator validation. When the agent submits, the orchestrator runs a four-step pipeline in a fresh sandbox that the agent cannot see or touch:
- Syntax check on the verifier script.
- Structural check against the mandatory Dockerfile template.
- Behavioral validation — build the Dockerfile from scratch and run the verifier in both the pre-patch state container (must exit non-zero) and the post-patch state container (must exit zero).
- Hacking detection — an LLM judge reads the verifier and rules whether it genuinely executes code or just pattern-matches its way to the right exit code. Runs on every submission.
If any step fails, structured feedback is passed back to the Builder, which attempts to rerun up to a user-defined maximum number of retries. If everything passes, the orchestrator writes the artifacts, marks the instance as passed, and moves on.
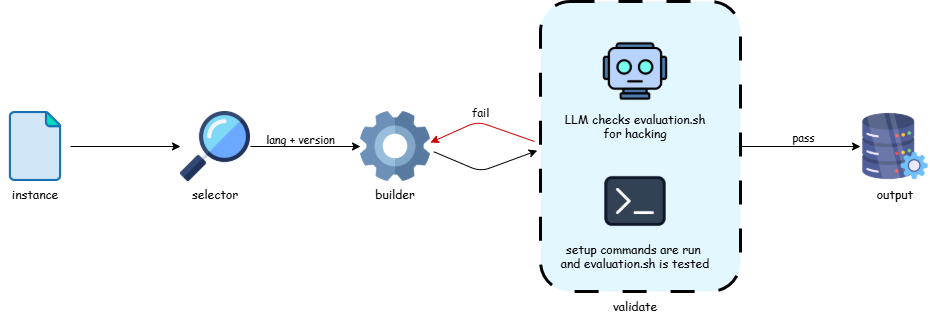 Figure 1. Illustrating the full process for building one instance
Figure 1. Illustrating the full process for building one instance Sweep mode is a small but useful wrapper on top of this loop. Instances are grouped by repo and ordered newest to oldest. The first commit in a repo runs a full agent build; subsequent commits in the same repo get the previously-successful spec as a hint, which drastically reduces turns taken and tokens consumed. If a streak of consecutive failures occurs in one repo, the sweep abandons that repo to prevent a stuck dependency story from burning the entire compute budget.
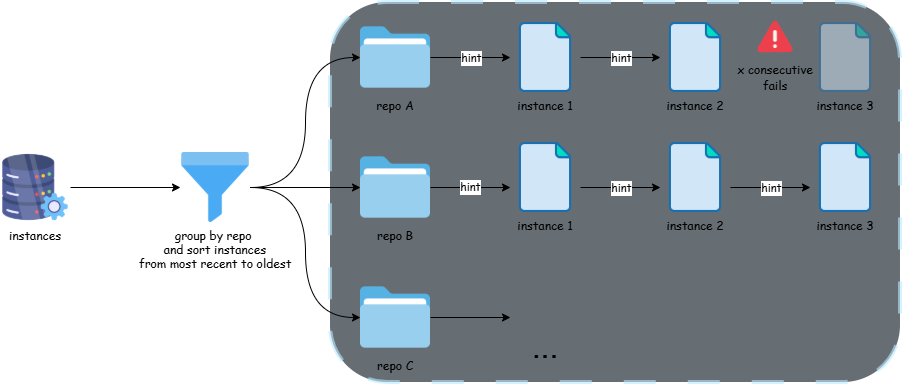 Figure 2. Illustrating how sweep mode looks.
Figure 2. Illustrating how sweep mode looks.Patch Agent
The Patch Agent splits a PR diff into a gold patch (production code) and a test patch (tests). This is harder than it sounds: tests sometimes share helper files with production code, framework-specific fixtures live in unexpected places, and the orchestrator has to prove that the two halves recombine exactly to the original.
First, the original diff is passed to a fast, programmatic splitting function that produces a first-cut split using a mix of filename patterns (tests/, *_test.go, *.spec.ts, conftest.py, and so on) and, for files those patterns don't classify, a tree-sitter pass that checks whether every added line falls inside a recognised test construct in that language (a def test_* function in Python, a describe/it/test call in JS/TS, a #[cfg(test)] module or #[test] attribute in Rust, a Test* function with a testing.* parameter in Go). The split is per-file: each diff --git section moves verbatim into one of the two outputs.
This first-cut split is then validated by the orchestrator. If validation passes, the orchestrator moves on to the next instance and the agent is never invoked. Otherwise the loop with the patch agent starts. The agent gets the two diffs generated by the AST based function, a checked-out repo at the base commit, the language hint from the env agent's Dockerfile, and the validator's specific failure message as initial context — so it iterates on the existing split rather than starting from scratch. It rewrites the two diff files; the orchestrator then validates the new attempt with the same pipeline.
- LLM judge. Reads the original patch, the gold portion, and the test portion, and rules whether the split is semantically clean — i.e. if the test half contains only test code and all the test code, and the gold half contains only non-test code.
- Apply the test portion, run the verifier — exit code must be non-zero. This is the strongest possible check that the test patch actually captures the failing tests from the PR. If the verifier passes here, the test portion is missing the tests that exercise the bug, or the gold portion is contaminated with test changes that belong in the test portion.
- Apply the gold portion on top, rerun the verifier — exit code must be zero. With both portions applied, behavior must match the resolved state. If not, the two portions together are not functionally equivalent to the original fix.
If any step fails, the failure message is fed back to the agent for a retry, up to a customisable limit.
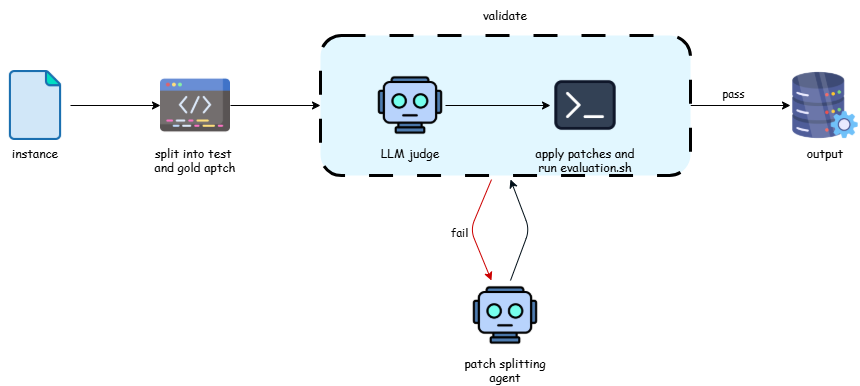 Figure 3. Patch agent
Figure 3. Patch agent In some cases, the patches have been split correctly but the evaluation.sh may rely on dependencies whose versions were not correctly pinned. In order to correct that, the patch agent is allowed to modify the evaluation.sh file before submitting to the orchestrator to be checked. In the event that the evaluation.sh file has been changed, the orchestrator will follow a similar path to Figure 3 above. It will first pass the original and modified evaluation.sh files to an LLM judge that will ensure the new evaluation.sh still correctly exercises the feature, and that the change is not too drastic. If that passes then it will validate the patches against this newly generated evaluation.sh file in the same way as described above.
Harbor Converter
The Harbor Converter takes a row that passed both env build and patch extraction and writes a Harbor task folder: environment, tests, solution, instruction, and a manifest. Instances missing any required field are skipped and tallied. The converter accepts either a JSONL file or a PostgreSQL table as input.
Results
We ran the pipeline on ~3,900 PR instances spanning Python, TypeScript, JavaScript, and Rust.
Env Agent: 1,900+ images built, for a build rate of just over 49%. We conducted a preliminary manual analysis into the causes of failure for the remaining 51% of the instances. Our conclusion is that these 51% failed because they are feature-implementation instances, not bug-fix instances. For a bug fix, an acceptable verifier can usually just call the affected code path and check that it no longer throws. For a feature implementation, we require more: the verifier has to either call existing functions from the codebase that exercise the new feature, or — when no such entry point exists — write its own tests that meaningfully check the feature is correctly implemented, not just that it runs without exceptions. That raises the bar for what a generated evaluation.sh is allowed to look like, and likely explains a non-trivial fraction of the failures.
Patch Agent: ~90% of the 1,900+ env-built rows split cleanly into gold and test halves. The 10% that don't are cases where "test" and "production" aren't cleanly separable at the file level: tests written inline at the bottom of a production source file, or in the case of Rust instances, #[cfg(test)] mod tests { ... } blocks interleaved with production code in the same file. A hunk-level split has to decide which lines inside a single hunk belong to which side, and the tree-hash check is uncompromising about getting that right.
Net usable yield: ~1,700 instances with a reproducible Dockerfile, a verifier whose exit code is the ground truth, and a clean test/gold split — ready to go into SFT or RL. Each instance corresponds to a built image in Harbor, the agent trajectory, and a pass-rate signal that can be used directly as a reward.