Before You Score the Model, Score the Benchmark: A Skeptical View Into Current Agentic Software Engineering Benchmarks
2026-05-04
TL;DR
- We surveyed several SWE benchmarks across bug-fixing and feature-implementation domains, and each had its own pros and cons — but the most pervasive issue was that the human-authored gold patch doesn't reliably resolve tasks, leaving every model score on top of it built on shifting ground.
- We substantially increased the stability of FeatBench, diagnosed its harness and environment problems, and lifted gold patch resolution from 37.31% ± 1.88 to 99.81% ± 0.10 while preserving 99%+ of the original instances and tests.
- We contributed back to the community by porting our fixes upstream to FeatBench, building a Harbor adapter, and releasing FeatBench-Verified v1.3.
Introduction
The software engineering (SE) community has been captivated by the rise of agentic SWEs. As these AI agents evolve, we are naturally shifting our focus from simple bug fixes to the significantly more complex task of full-blown feature implementation.
However, evaluating these agents introduces a profound challenge that did not exist in earlier AI domains, such as image classification. While in those fields, the "gold" ground-truth patch would guarantee a 100% resolution rate, achieving this ceiling in software engineering benchmarks is neither easy nor straightforward, even when using an Oracle (the gold patch itself). The sheer friction of environment building, combined with the instability of test execution, creates a significant infrastructural noise problem.
If we can't reliably spin up environments and run tests—if the perfect solution can't consistently achieve 100% success—we can't trust the benchmarks or meaningfully evaluate the agents. As part of an internal project diving into SE agent benchmarks, we decided to lift the hood on current standard datasets to investigate this discrepancy. What we found was a concerning amount of infrastructure noise and fundamental flaws.
The Cracks in SWE-Bench
For anyone building or evaluating AI coding agents, SWE-bench is a familiar name — the de facto standard for measuring an agent's ability to resolve real-world GitHub issues within complex Python repositories. Naturally, we began here, using OpenHands (v0.50) as our agentic scaffold. Almost immediately, the cracks started to show.
Our first roadblock was an integration mismatch between the scaffold and the benchmark's environment. SWE-bench operates out of a /testbed directory, where the editable pip install lives. OpenHands, however, copies files to a separate /workspace directory without re-running pip install -e ., so the model's changes are never reflected when evaluation tests execute.
That was a scaffold-specific hurdle we could work around. Far more concerning was the realization that the gold patches themselves were not consistently resolving.
Sit with that for a second. The gold patch is the literal human-authored fix that the project maintainers reviewed, merged, and shipped — it is, by definition, the correct answer. If the correct answer can't reliably produce a passing test run, every score we report for an AI agent is fundamentally contaminated. Is a model scoring 45% actually failing on 55% of problems, or is some unknown fraction of those "failures" the same environmental flakiness that drags gold below 100%? Without a stable ground-truth ceiling, we're not measuring capability — we're measuring capability plus noise, with no principled way to separate the two. When the ceiling moves, every number downstream of it moves too, and cross-model comparisons stop meaning very much.
In our initial setup, only 454 out of 500 (90.8%) instances were resolved using the official gold patch. After pulling the official SWE-bench images again, our success rate jumped to 481 (96.2%). We suspect the original issue was due to how images were built in our initial setup. The remaining 19 failures were a mix of three known astropy repository failures, general test flakiness, and infrastructure noise from our network configuration.
That last issue highlights a significant pain point for enterprise users. Since we operated on a corporate network, we were required to inject HTTP proxy environment variables into Docker containers — and several repository instances couldn't handle them gracefully, resulting in test failures. Benchmark evaluation infrastructure needs better solutions here, such as host-side forward proxies (Cntlm or Squid), rather than forcing variables into containers.
The open-source community has stepped up on some fronts — Issue #484 and the Verified gold fixes dataset patch the known astropy problems — but fundamental environment stability issues remain largely unsolved.
To isolate proxy effects, we spun up a pristine environment outside of our internal network and ran 10 independent Oracle (gold patch) runs. Even here, results were imperfect: 491 (98.2%) instances resolved consistently across all 10 runs, 2 resolved in 9 out of 10 (flaky tests), and 7 failed every time. This averages to 492.8 / 500 (98.56%) resolved.
While 98.5% sounds high in a vacuum, a moving ceiling means your evaluation metrics are fundamentally noisy. Community reports echo similar frustrations (#267, #294, #274, #246, Harbor Troubleshooting).
It turns out we weren't alone in noticing this. In February 2026, OpenAI publicly deprecated SWE-bench Verified for frontier evaluation 1, citing exactly the ground-truth problem we were hitting — plus a bigger one. Their audit found that at least 59.4% of the audited problems had flawed test cases that reject functionally correct submissions, and that every frontier model they tested — GPT-5.2, Claude Opus 4.5, Gemini 3 Flash — could reproduce original human-written solutions or quote verbatim problem details they should never have seen. Improvements on Verified, they concluded, increasingly reflect how much the model was exposed to the benchmark at training time rather than real capability gains.
There's also a subtler problem with what SWE-bench actually measures. A recent Microsoft paper, Saving SWE-Bench 2, argues that GitHub-issue-derived benchmarks fundamentally misrepresent how developers use coding agents in practice — most real interaction happens through informal chat in an IDE, not through the structured prose of a filed issue. When the authors mutated SWE-Bench tasks into realistic chat-style queries, they found existing benchmarks significantly overestimate agent capabilities by more than 50% over baseline performance on public benchmarks. So even setting ground-truth noise aside, the benchmark may be measuring the wrong interaction paradigm entirely.
And finally, there's simple saturation. Claude Opus 4.7 now posts 87.6% on SWE-bench Verified 3, and top models have clustered in the 70–80%+ range for months 4. When every frontier model is bumping against the same noisy ceiling, differences between them stop telling you anything meaningful — you're reading signals out of the gap between 78% and 81% while the gold patch itself fluctuates by a point or two 5.
Put together — unstable ground truth, a task format that doesn't reflect real usage, and a saturated ceiling — SWE-bench stopped being the right place to stress-test agents. We looked further afield and landed on feature implementation.
Moving to Feature Implementation Benchmarks
The first thing we noticed in the Feature Implementation (FI) literature is that many people have already created benchmarks that claim to measure Feature Implementation capability. Specifically: FeatureBench, FEA-Bench, and FeatBench. Those are three different benchmarks from three different groups, released within a window of months, with nearly identical names. We had to keep tabs open just to remember which was which. It's a small naming crisis, and we enjoyed it.
What's actually different between them is how each one selects and curates its FI tasks — and the choices there have real downstream consequences for evaluation.
-
FeatureBench 6: Defines a feature as something that spans multiple PRs across a scattered timeline. Traces unit tests along a dependency graph to isolate feature-level tasks, with an LLM-as-a-judge categorizing relevant imports as a secondary filter.
- The flaw: Because problem statements are LLM-synthesized from test graphs rather than drawn from real PR descriptions, tasks feel artificial — and they are extremely hard. The paper reports Claude 4.5 Opus, which achieves an 80.9% resolved rate on SWE-bench but succeeds on only 11.0% of FeatureBench tasks. A ceiling in the low double digits means we'd mostly be measuring floor noise rather than capability differences — the same signal-to-noise problem as SWE-bench, just at the opposite end of the scale.
-
FEA-Bench 7: Created by Microsoft. Looks at GitHub PRs introducing new components (classes, functions) that account for more than 25% of all edited lines in the gold patch, resulting in substantially longer code generation than SWE-bench.
- The flaw: A major contradiction — the definition requires a new component, yet 116 of 1401 tasks have an empty
new_componentslist. Some task descriptions are literally just an issue number. The original implementation isn't truly agentic (Oracle + BM25 retrieval), and a bug causes the FEA-Bench repo's README to appear in the model's context instead of the actual instance repo files. Despite all that, our 5 Oracle runs yielded a respectable 83.5% mean resolution — though we abandoned efforts to fix the image-build issues.
- The flaw: A major contradiction — the definition requires a new component, yet 116 of 1401 tasks have an empty
-
FeatBench 8: Uses an LLM to identify feature PRs from release histories, filters for Python changes and test patches, and requires pure natural-language prompts with no code hints. Smaller and more curated: 156 instances from 25 actively maintained repos, with Fail-to-Pass (F2P) and Pass-to-Pass (P2P) tests to verify correctness and prevent regressions.
- The flaw: FeatBench restricts tasks to PRs that modify existing functions — PRs that add or remove functions outright are filtered out to keep tests reliable. That's a softer choice than FEA-Bench's upfront signature hints, but it does narrow what "feature implementation" means, since real features often introduce or retire functions. Separately, the released harness is research-grade, and our Oracle (gold patch) runs came back looking nothing like ground truth should. More on that in the next section.
On balance, we still picked FeatBench. Every FI benchmark we looked at makes a trade-off somewhere: FeatureBench accepts artificiality to scale task generation, FEA-Bench accepts ambiguous tasks and some dataset contradictions to chase volume, and FeatBench accepts a narrower scope of function modification in exchange for reliable testability. Of those, FeatBench's tradeoff sits in the best place for our purposes — it's a scope tradeoff rather than a task-quality one, and the tasks that do make the cut are grounded in real PRs with pure natural-language prompts that mirror how developers actually talk to coding agents (directly answering the Saving SWE-Bench critique). Its reported ~30% SOTA ceiling lands in the sweet spot where benchmark signal is still meaningful, and its evolving data pipeline pushes back on the contamination story that killed SWE-bench Verified. We felt good about the foundation; the harness-level rough edges were plumbing we could take on ourselves.
So: benchmark picked, sleeves rolled up. If our SWE-bench experience was any indication, the interesting parts of this story were going to happen in the environment, not the agent — and we weren't disappointed.
Deep Dive: Fixing FeatBench
Having committed to FeatBench, we started running experiments — and immediately ran into friction, even with the officially released Docker images.
The evaluation harness is research-grade, which is what you'd expect from a first-release artifact alongside a paper: a handful of rough edges and no concurrency support. End-to-end, a single experiment can take close to a week.
Speed aside, our resolved rates were also lower than expected. Running GPT-5 with the default setup, we got 21.8% — noticeably lower than the 29.94% reported in the paper. Some tasks consistently failed under the gold patch on our end, even though the authors' released result files marked them as resolved for GPT-5. The clearest pattern was in the Conan repo instances, which make up roughly a third of the dataset and failed every time due to what appears to be a CMake configuration issue. Our best guess is environmental drift — something in the original setup that our replication didn't pick up.
To establish a baseline, we ran 5 Oracle runs on the unmodified dataset, expecting something close to 100%. Instead:
- Mean: 37.31%
- Std Dev: 4.21%
- Std Error: 1.88%
A 37% mean on ground truth was the signal that the environment needed work before we could trust any downstream number.
Step 1: Environment Patches (The v1.1-Verified Attempt)
Rather than move on, we invested in getting FeatBench running properly. We applied a set of environment-dependency patches, producing a modified harness we called v1.1. The impact was immediate: our GPT-5 agent score jumped to 41.03%. That's nearly double our pre-patch 21.8% and above the paper's 29.94%, which suggests much of the earlier gap was environmental noise rather than model capability. Oracle, though, still wasn't near 100%:
- Mean: 83.33%
- Std Dev: 1.92%
- Std Error: 0.86%
A real improvement, but short of the stability you want from a benchmark. To push further, we isolated the 112 instances that passed consistently across all 5 Oracle runs and called this subset v1.1-Verified. Across 8 Oracle runs on the curated subset, the numbers looked much better:
- Mean: 98.66%
- Std Dev: 1.17%
- Std Error: 0.41%
Meaningfully more stable — but it came at a cost. We had set aside a large chunk of the dataset to get there, and even then, we weren't consistently hitting 100%. We tried to recover ground with v1.2-Verified (131 instances), selectively excluding flaky P2P tests that were irrelevant to the gold patch rather than dropping entire instances. It didn't land as cleanly as we'd hoped: new sources of variance crept in, and the average resolution rate dipped to 84.54% over 4 runs.
The Flakiness Problem
To visualize the underlying noise, we ran 20 independent Oracle runs on the original dataset with harness v1.1. The resolution rate continuously degrades across runs without ever settling into a plateau.
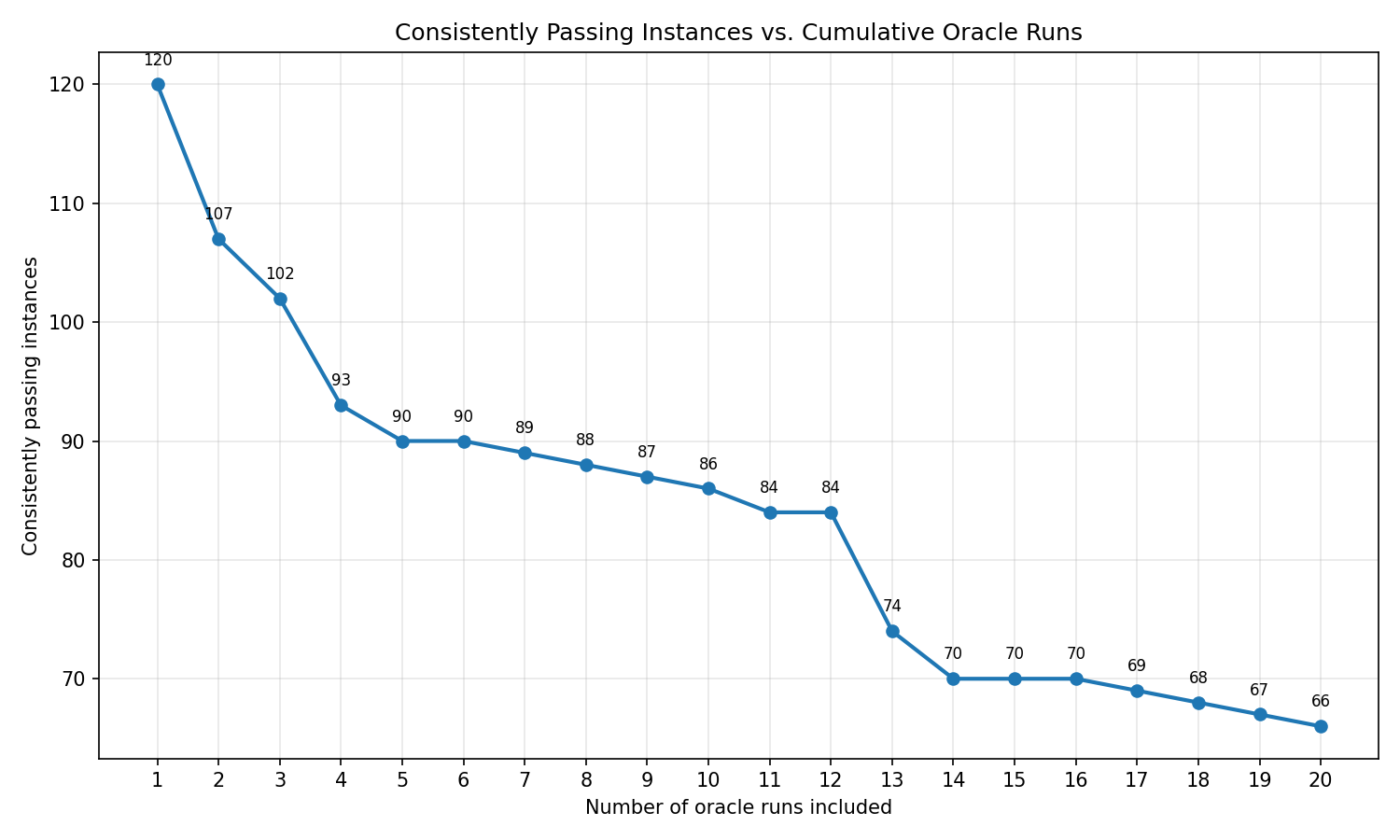
Cumulative Oracle consistent resolution across 20 runs on the original FeatBench dataset. Infrastructure noise causes a continuous decline in reliability without reaching a stable plateau.
Only 66 instances (42.3%) were consistently passing with the goldpatch across 20 runs. With this level of infrastructure noise, identifying root causes for test failures is like finding a needle in a haystack.
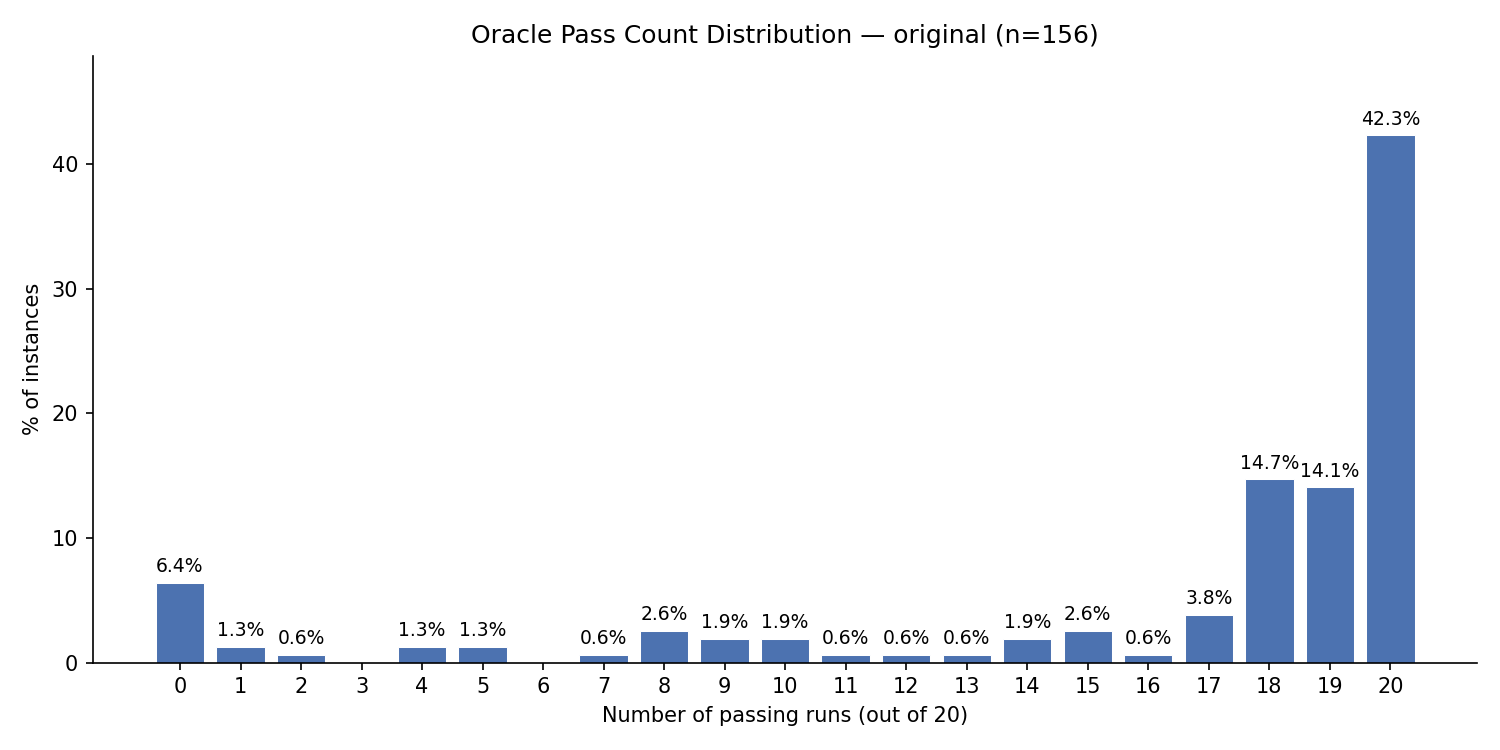
Per-task resolution rate over 20 Oracle runs on the original dataset. Many tasks pass or fail arbitrarily between runs, showing wide variance across the benchmark.
By contrast, here is the stability profile of our tightly filtered v1.1-Verified dataset, which gave much more consistent results.
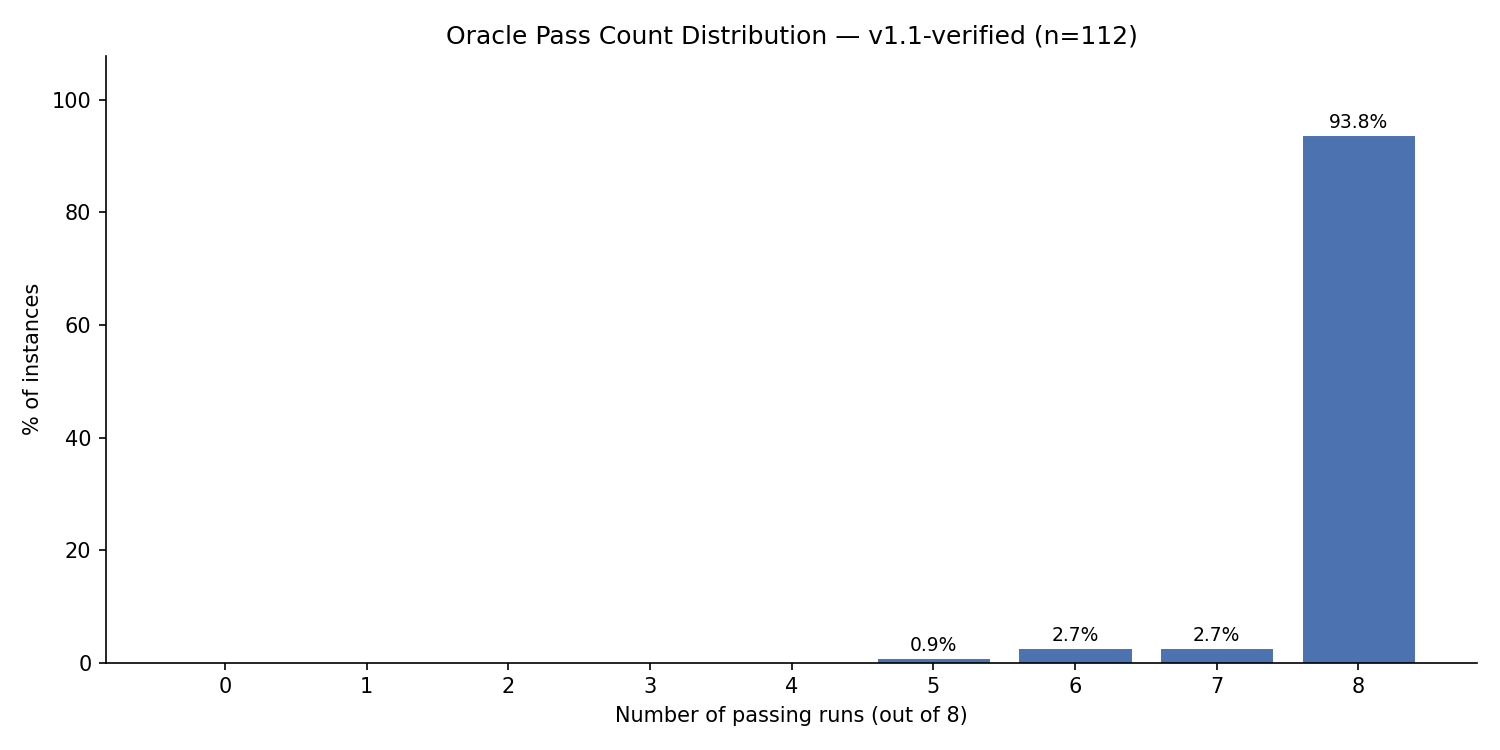
Per-task Oracle resolution on the v1.1-Verified subset. Most tasks now have a high resolution rate, clustering near 100%, with drastically reduced noise compared to the full benchmark.
Step 2: Transitioning to Harbor (The v1.3-Verified Attempt)
Tired of fighting the harness, we switched to Harbor 9, a standardized platform capable of running any supported agent with any supported benchmark. We implemented the Harbor adapter for FeatBench (which has since been merged).
Harbor's concurrency, resource management, and container orchestration made stability much easier to get. With flakiness manageable, we worked through the remaining test-runner issues:
- Pytest Selection: Passing individual test paths to pytest caused unexpected failures. We pivoted to running tests at the file level and only checking the status of the expected tests for grading.
- Xdist Concurrency: Some tests failed when run concurrently via xdist or alongside other files. We identified these and created explicit rules to isolate them.
- Dependencies & Memory: We fixed remaining missing module installations and strictly adjusted memory resources per task, a critical step highlighted in a recent Anthropic blog post 5. This avoids instances running into out-of-memory issues, especially for memory-intensive repositories.
The results were night and day (Original v1.0 benchmark):
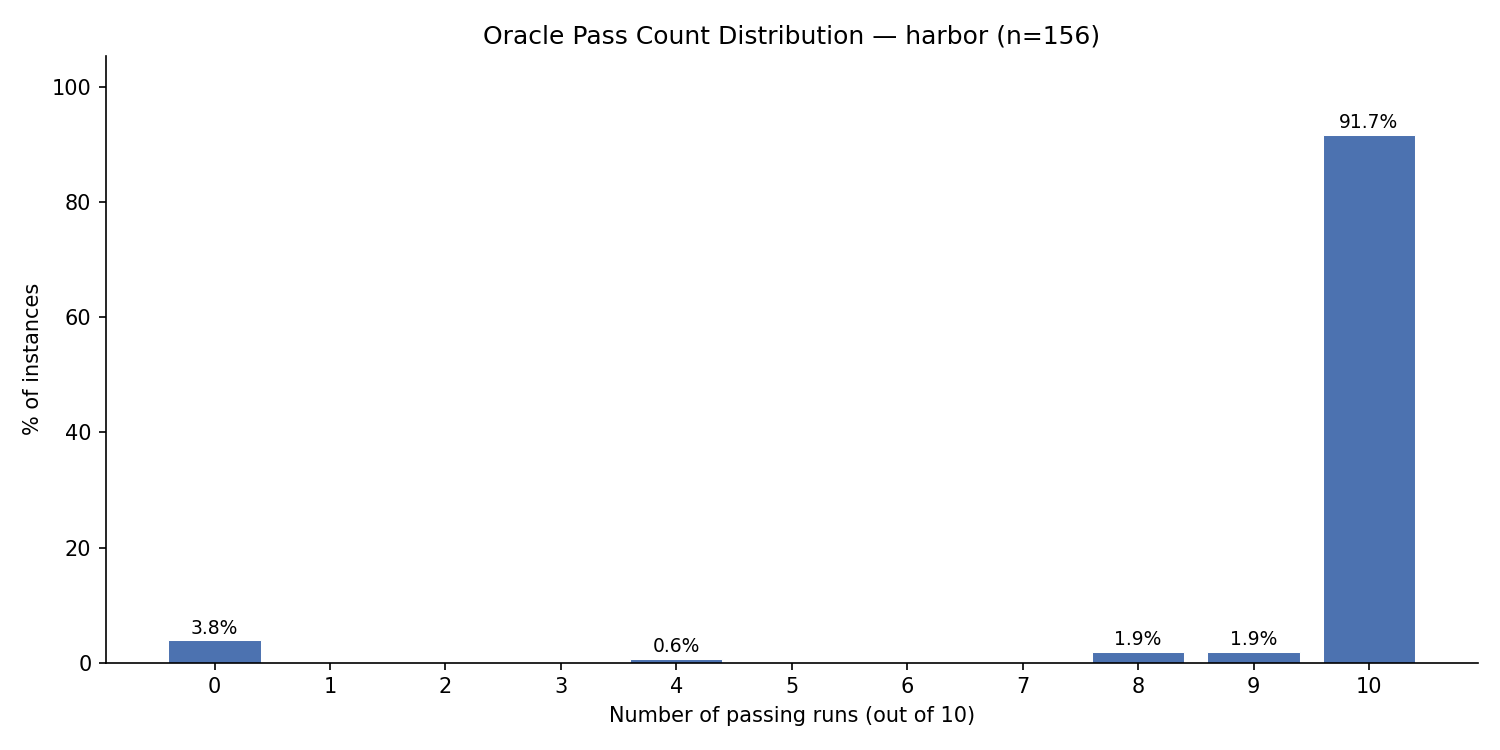
Per-task Oracle resolution after migrating to Harbor and resolving pytest and resource constraints, evaluated on the original v1.0 FeatBench dataset. Near-perfect stability across tasks.
We removed the few remaining consistently failing/flaky tasks to create v1.3-Verified. Out of 10 Oracle runs, 7 runs hit a flawless 100%.
- Mean: 99.81%
- Std Dev: 0.31%
- Std Error: 0.10%
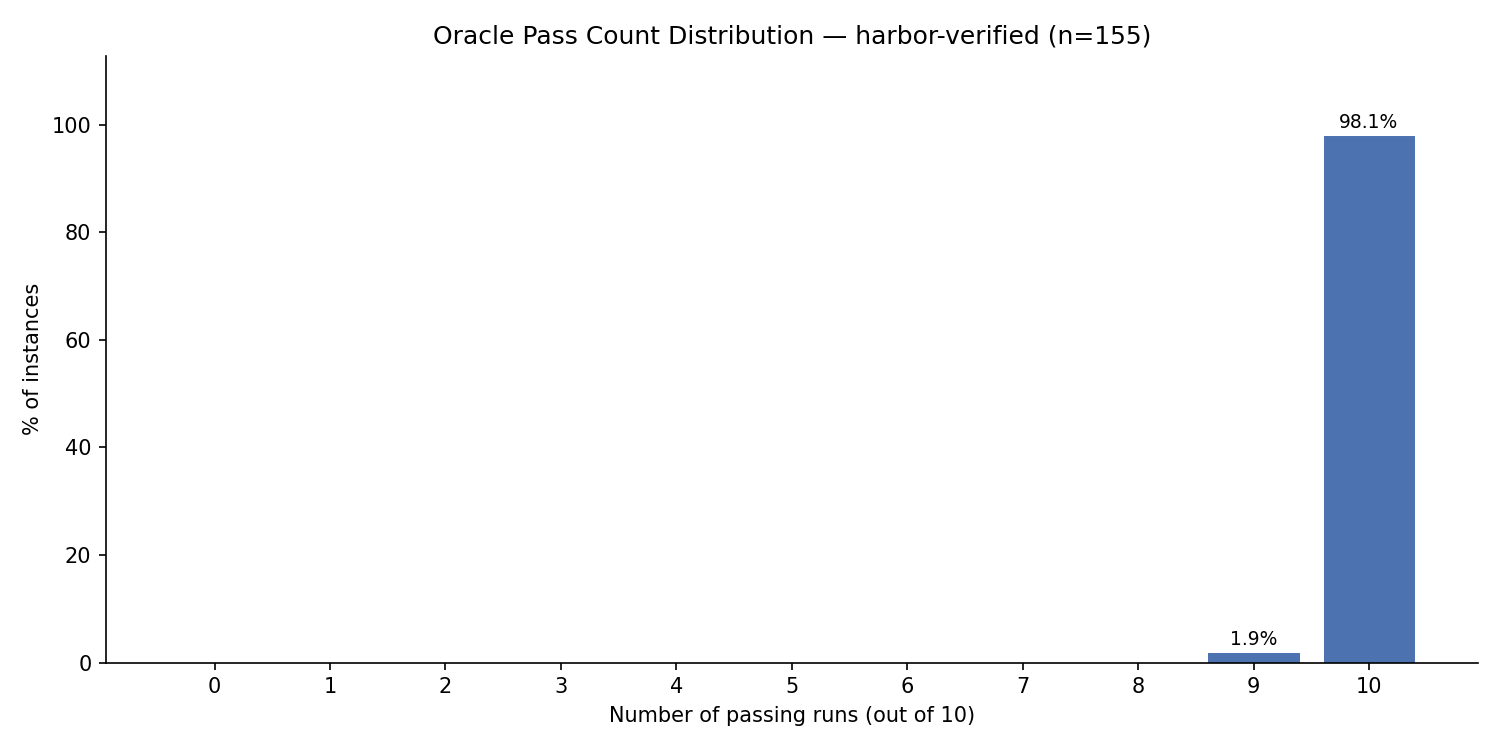
Per-task Oracle resolution on v1.3-Verified under Harbor. Peak consistency across the dataset.
We're now at 98.1% of instances consistently passing — a substantial jump from where we started at 42.3%. Near-perfect Oracle resolution, with the benchmark holding onto its discriminative power along the way: we kept 99.3% of the original instances and 99.8% of the test cases.
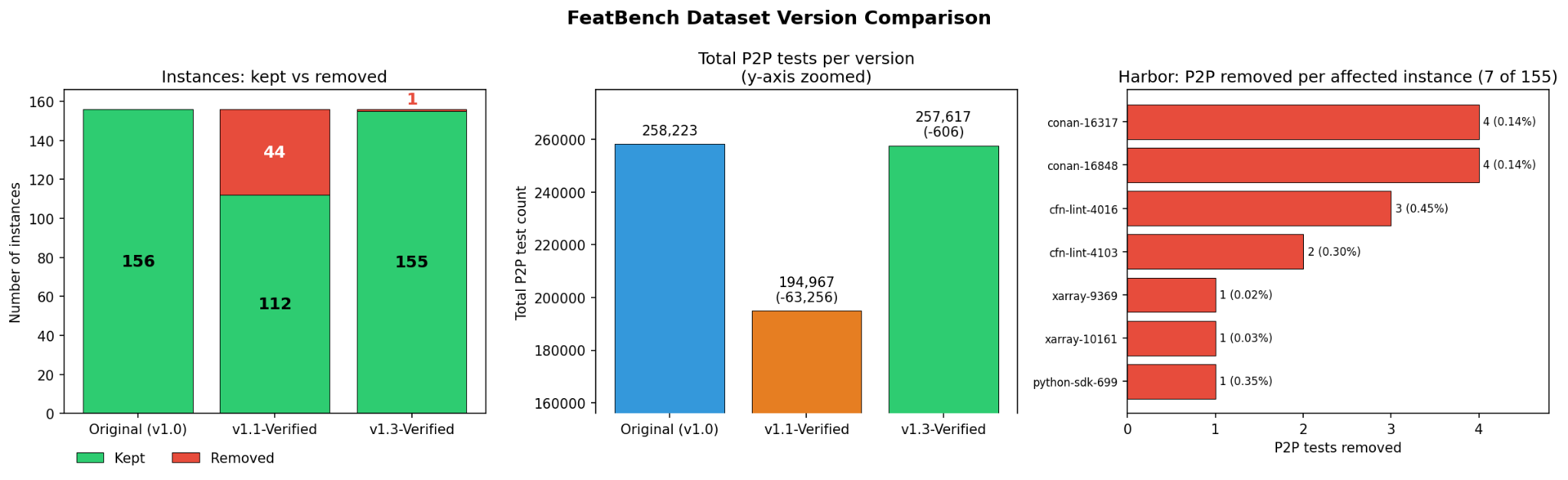 Comparison of the three FeatBench versions we experimented on.
Comparison of the three FeatBench versions we experimented on.Porting Back and Community Contribution
To ensure the community benefits, we ported these instance-specific patches back to the original FeatBench harness (creating harness v1.2). To address the inherent instability of the original harness, we also added a retry mechanism during the test run.
Here is how the original harness performed with our patches:
- w/o retry: Mean 87.71% | Std Dev 5.25% | Std Error 2.14%
- w/ retry: Mean 94.36% | Std Dev 2.81% | Std Error 1.26%
We have fully integrated both FeatBench and its original agent (Trae-agent) into Harbor:
- FeatBench PR: harbor-framework/harbor#1218
- Trae-agent PR: harbor-framework/harbor#1298
- Parity Experiments: Harbor Adapter Featbench Parity
We also opened issues and PRs on the original FeatBench repository. As of writing, we have received no response:
Summary of FeatBench Oracle Experiments
The table below clearly outlines our journey from the broken original environment to a highly stable, verifiable benchmark.
| Dataset Version | Setup & Environment Fixes | Runs | Mean Resolution | Std Dev | Std Error |
|---|---|---|---|---|---|
| Original FeatBench (156 tasks) | Original Harness | 5 | 37.31% | 4.21% | 1.88% |
| Original FeatBench (156 tasks) | Partially Patched Harness (v1.1) | 5 | 83.33% | 1.92% | 0.86% |
| v1.1-Verified (112 tasks) | Partially Patched Harness (v1.1) | 8 | 98.66% | 1.17% | 0.41% |
| v1.2-Verified (131 tasks) | Partially Patched Harness (v1.1) | 4 | 84.54% | 8.30% | 4.15% |
| Original FeatBench (156 tasks) | Harbor Framework | 10 | 95.19% | 0.92% | 0.29% |
| v1.3-Verified (155 tasks) | Harbor Framework | 10 | 99.81% | 0.31% | 0.10% |
| Original FeatBench (156 tasks) | Patched Harness v1.2 (No Retry) | 6 | 87.71% | 5.25% | 2.14% |
| Original FeatBench (156 tasks) | Patched Harness v1.2 (With Retry) | 5 | 94.36% | 2.81% | 1.26% |
What We're Releasing
To make the work above easy to build on, we're open-sourcing everything we produced along the way.
Recommended path for most users: run FeatBench-Verified v1.3 through the Harbor adapter. That combination is what we landed on as the most stable, best-supported setup.
- FeatBench adapter for Harbor (recommended runner): harbor-framework/harbor/adapters/featbench
- FeatBench-Verified dataset (recommended dataset): PGCodeLLM/FeatBench-Verified. Revisions matter here:
- v1.3 revision → v1.3-Verified (155 instances, recommended)
- v1.1-evalhub revision → v1.1-Verified (112 instances, earlier curated subset)
- Original FeatBench dataset, mirrored on the Hugging Face Hub for convenience (156 instances): PGCodeLLM/FeatBench
- Patched original FeatBench harness, for users who prefer to stay on the upstream-style harness rather than migrating to Harbor:
What Does the Future Look Like?
If there's one takeaway from this exercise, it's this: benchmarks should be validated with both an Oracle (gold patch) run and a no-op agent run — an "agent" that does nothing and submits an empty patch — before anyone runs a real model on them. In an ideal world, the Oracle hits 100%, and the no-op hits 0%. In practice, oracle bound won't be met perfectly; as Anthropic's recent work on infrastructure noise in agentic evals 5 documents, some run-to-run variance is inherent in end-to-end evaluation systems and is difficult to eliminate entirely. What matters is that the noise is small and well-characterized — for example, Oracle hitting 100% on most repeats and missing by only a small margin on the rest (i.e., a tight pass@k). Without that kind of bounded, quantified ceiling and floor, every downstream number sits on an unknown amount of noise.
Looking further out, we think the community would benefit from a few shifts:
- Environment-building agents. Building clean, reproducible benchmark environments is itself a hard engineering problem — probably harder than most of the tasks inside the benchmarks. Efforts like RepoLaunch 10, which automates dependency resolution, compilation, and test extraction across languages and platforms, will become increasingly important as benchmarks grow in scope.
- A low tolerance for infrastructure noise. An agentic benchmark without a reliable environment doesn't really measure the agent — it measures the agent plus the environment, in unknown proportions. Stability needs to be a first-class requirement, not something the evaluation community works around after the fact.
- Standardized evaluation platforms. Tooling like Harbor makes it straightforward to plug different agents into different benchmarks without re-implementing harnesses each time. That saves work for benchmark authors and pushes task formats toward a shared baseline — and, just as importantly, frees authors to spend their effort on problems that actually need their expertise, like the evaluation-robustness failures recently surfaced by the Berkeley RDI team 11, who showed that every major agent benchmark they audited could be exploited for near-perfect scores without solving a single task. Authors shouldn't have to spend their time on harness plumbing when deeper problems like these are waiting.
- A sharper, shared definition of "feature implementation." Coding agents have moved well past the code-completion era; they're writing multi-file diffs, navigating real repos, and taking on work that used to require a human engineer. The benchmarks we use to measure them need to keep pace — which means being precise about what counts as a feature, what scope it spans, and how we tell a well-scoped task apart from a bug fix or a refactor in disguise. The three near-identically named FI benchmarks we surveyed each answer that question differently, and until the community converges on a shared answer, it's hard to compare results across them or to claim that a model is genuinely good at "feature implementation" rather than at one particular group's operationalization of it. Until the foundations are solid, the numbers on top of them won't mean as much as we'd like them to.
Acknowledgements
Many thanks to Boyuan Chen, Gustavo Oliva, and Ahmed E. Hassan for their help and thoughtful feedback on earlier drafts of this post, and to Arthur Leung, Yihao Chen, Akki Singh, Shenyu Zheng, Zifan Zhu, Miles (Milad) Soltany, Sogol Masoumzadeh, and the other members of our team who helped with this work.
We're also grateful to the Harbor team for their work on the framework itself and for keeping the review cycle on our PRs short and substantive — particularly Lin Shi (Adapter Team Lead), who shepherded the FeatBench adapter through review, as well as Crystal Zhou, Zixuan Zhu, Boxuan Li, and Alex Shaw for their reviews on the related PRs.
Citation
@misc{shayanfar2026,
title = {Before You Score the Model, Score the Benchmark: A Skeptical View Into Current Agentic Software Engineering Benchmarks},
author = {Radin Shayanfar, Keheliya Gallaba},
howpublished = {\url{https://centre-for-software-excellence.github.io/docs/blog/before-you-score-the-model-score-the-benchmark}},
year = {2026},
}References
Footnotes
-
Why SWE-bench Verified no longer measures frontier coding capabilities ↩ ↩2
-
Saving SWE-Bench: A Benchmark Mutation Approach for Realistic Agent Evaluation ↩ ↩2
-
Code Generation Benchmarks 2026: SOTA LLMs for Programming ↩ ↩2
-
Quantifying infrastructure noise in agentic coding evals ↩ ↩2 ↩3 ↩4
-
FeatureBench: Benchmarking Agentic Coding for Complex Feature Development ↩ ↩2
-
FEA-Bench: A Benchmark for Evaluating Repository-Level Code Generation for Feature Implementation ↩ ↩2
-
FeatBench: Towards More Realistic Evaluation of Feature-level Code Generation ↩ ↩2
-
Harbor: A framework for evaluating and optimizing agents and models in container environments ↩ ↩2
-
RepoLaunch: Automating Build & Test Pipeline of Code Repositories on ANY Language and ANY Platform ↩ ↩2
-
How We Broke Top AI Agent Benchmarks: And What Comes Next ↩ ↩2